Episode Details
Back to Episodes“Dissolving the Deep Learning Sample Efficiency Gap” by Samuel Knoche
Description
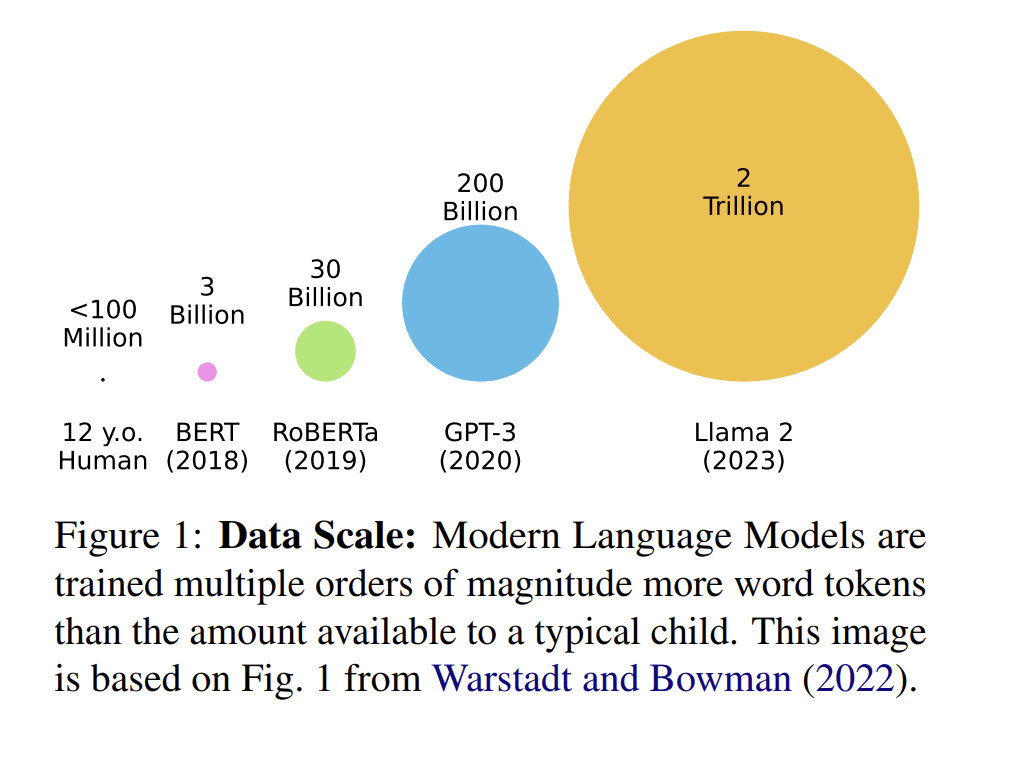
A common observation about deep learning is that it's wildly sample inefficient compared to humans. Deep learning systems appear to need much more real data or environment interaction to reach a given level of capability. A teenager can learn to drive in a few dozen hours; self-driving systems are trained for years on billions of miles of data. A human can become competitive at StarCraft II in well under a year of play, while AlphaStar required imitation learning from roughly 18 years of human games followed by 13,300 years of self-play to reach Grandmaster[1]. A 12-year-old has heard perhaps a hundred million words of language; a frontier LLM trains on tens of trillions of tokens. The gap is, on the face of it, enormous.
(From Warstadt et al. 2025)
(From Byrnes 2025)
What people take this to mean varies widely. Steven Byrnes appears to read the gap as evidence that current algorithms are far from what the brain is doing, such that much better algorithms must be waiting to be found. His guess is that human-level, human-speed AGI will require not a datacenter but "one consumer gaming GPU," even for training from scratch.[2] Yarrow Bouchard on the [...]
---
Outline:
(02:40) 1. All about the priors
(03:17) a. Human priors
(06:33) b. Good representations enable fast learning
(08:24) 2. Model-based RL
(09:16) a. Dreamer
(12:02) b. EfficientZero V2
(15:36) 3. Other Low-Hanging Fruit
(16:24) a. Training Language Models via Neural Cellular Automata
(18:44) b. Synthetic bootstrapped pretraining
(20:51) c. Algorithmic progress and the Pareto frontier
(21:59) 4. Evolution, optimizers, and hard-coded reward functions in the cortex
(22:50) a. Optimizer
(24:42) b. Reward functions
(27:11) 5. Size matters
(27:15) a. Data efficiency and scaling laws
(28:52) b. Why it matters in particular in the case of self-driving cars
(31:16) 6. Implications
(31:20) a. On brain in a box in a basement
(34:12) b. On sample efficiency being an unsolved research problem
(36:29) Conclusion
(37:11) Appendix: How Much Multimodal Data Does a Child Actually Receive?
(39:28) Visual input over 12 years
(39:45) Frontier text corpus, 2026
(40:03) Visual / text ratios at age 12
The original text contained 19 footnotes which were omitted from this narration.
---
First published:
June 1st, 2026
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us