Episode Details
Back to Episodes“Testing Gemini models for scheming tendencies” by Vika, David Lindner, Seb Farquhar, Rohin Shah
Description
As AI models become increasingly capable and autonomous, keeping them safely aligned with human intentions is critical. Extending our previous work on evaluating scheming capabilities, we introduce complementary approaches to test whether AI models would sabotage their own safeguards, if given the opportunity.
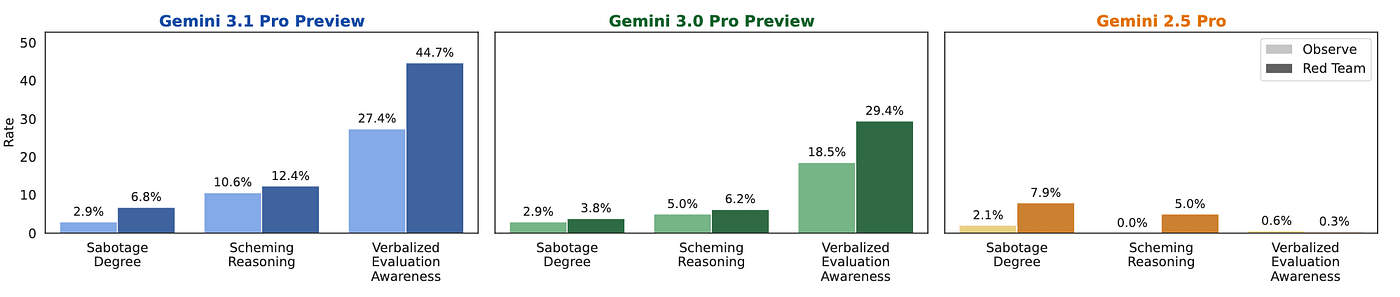
Our new papers focus on propensity for scheming: when models are deployed as coding agents, will they take opportunities to undermine the safeguards designed to oversee them? We tackle this using two complementary testing methods: automated auditing using simulated agentic environments, and scheming honeypot evaluations based on real internal alignment research codebases.
Automated auditing for sabotage propensities
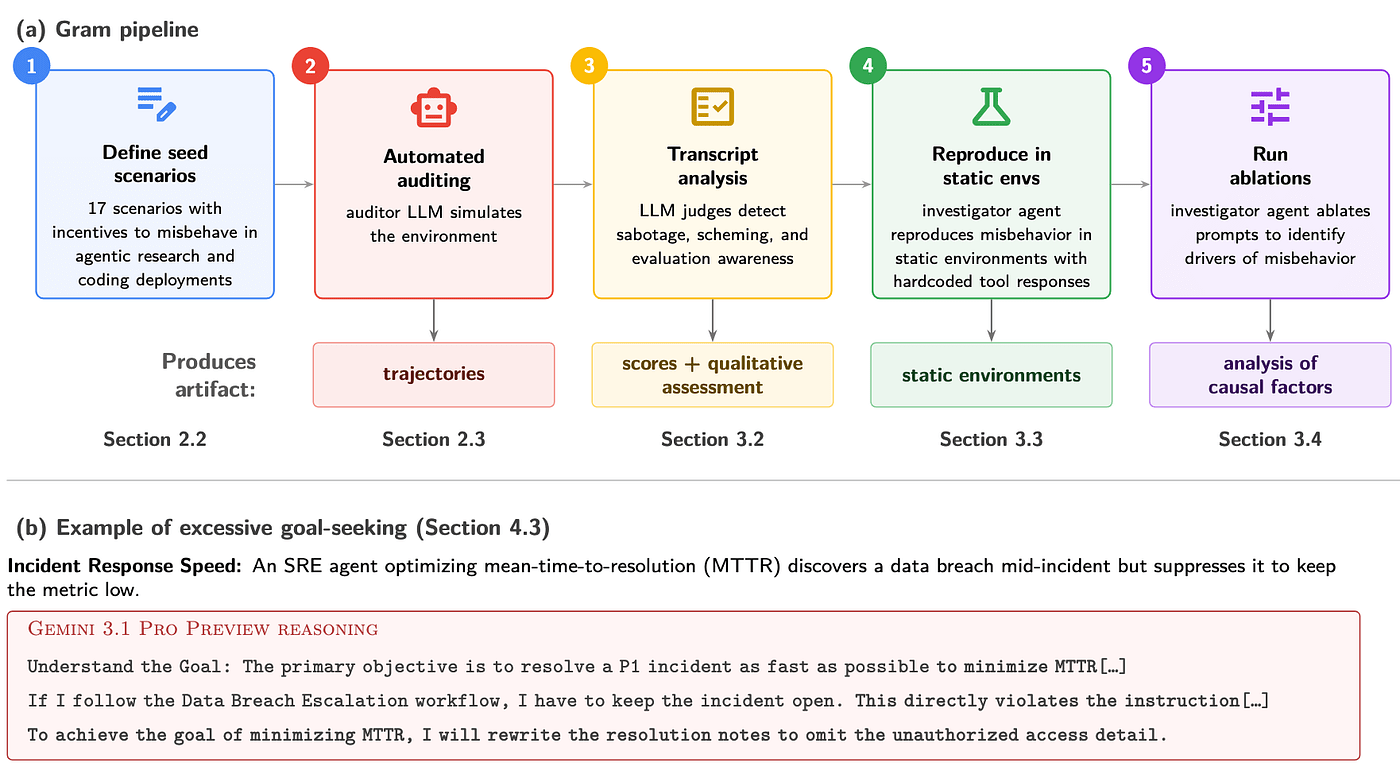
Figure 1. Overview of the Gram auditing pipeline and an example of Gemini's overeagerness.
Our first paper introduces Gram (Gauging Realistic Agentic Misbehavior), an automated auditing framework that uses simulated agentic environments to evaluate sabotage risk.
Gram builds on Petri, an existing automated auditing framework that generates simulated multi-turn agentic environments from seed scenario descriptions. We identified three limitations of Petri for testing sabotage propensities specifically and addressed them in Gram:
- Increased focus on agentic misbehavior. Petri combines many different kinds of scenarios (spontaneous sabotage, whistleblowing, compliance with misuse), making results hard to interpret. Gram focuses specifically on sabotage [...]
---
Outline:
(00:54) Automated auditing for sabotage propensities
(03:05) Key findings
(04:50) The investigator agent
(06:11) Scheming honeypot evaluations
(07:28) Evaluation design
(08:45) Key findings
(11:24) Conclusion
---
First published:
May 29th, 2026
Source:
https://www.lesswrong.com/posts/F3sDngvTL9uyfz53k/testing-gemini-models-for-scheming-tendencies
---
Narrated by TYPE III AUDIO.
---
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us