Episode Details
Back to Episodes“When Are Two Networks the Same? Tensor Similarity for Mechanistic Interpretability” by Logan Riggs, tdooms, Conflux, lwroe, MLNissenGonzalez
Description
We've found a method that tells you:
- How functionally similar two neural networks are across ALL inputs,
- Computed solely from the weights (i.e. no data),
- Using a principled generalization of cosine similarity.
There's only one catch: you have to use a tensor network.
We've already shown that tensor-transformer variants are performant (this isn't a novel claim, see these papers for MLPs and Attention), so here we're focusing on the interpretability advances.
Linear Algebra Applies to Tensors
A tensor network is just a specific decomposition of a tensor, d a tensor is just a generalization of a matrix. This means we can apply tools from linear algebra to our entire network in a principled way. In our paper, we focus on a generalization of cosine similarity we call tensor similarity.
The most direct result is:
The expected inner product of the activations of two multilinear models under a Gaussian input (i.e. functional similarity on gaussian inputs) is equal to their weight-space inner product (ie tensor similarity)
Let's look at our baselines:
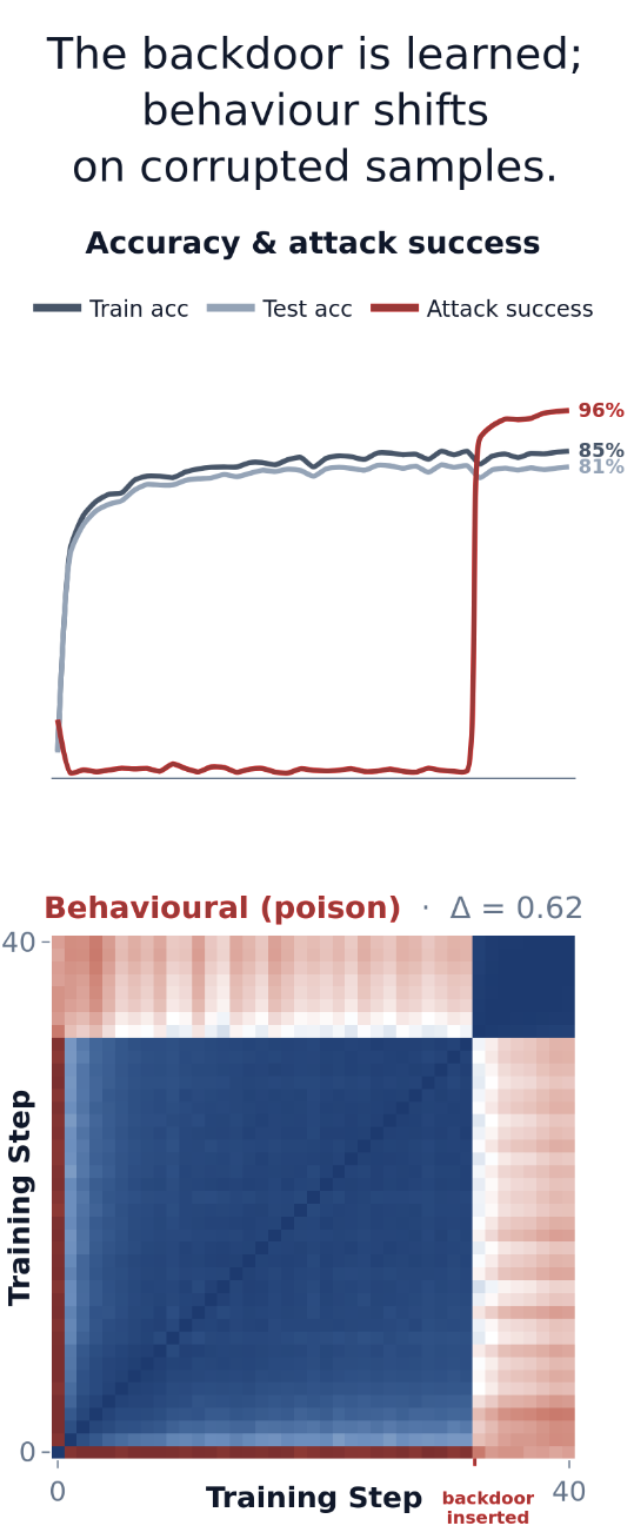
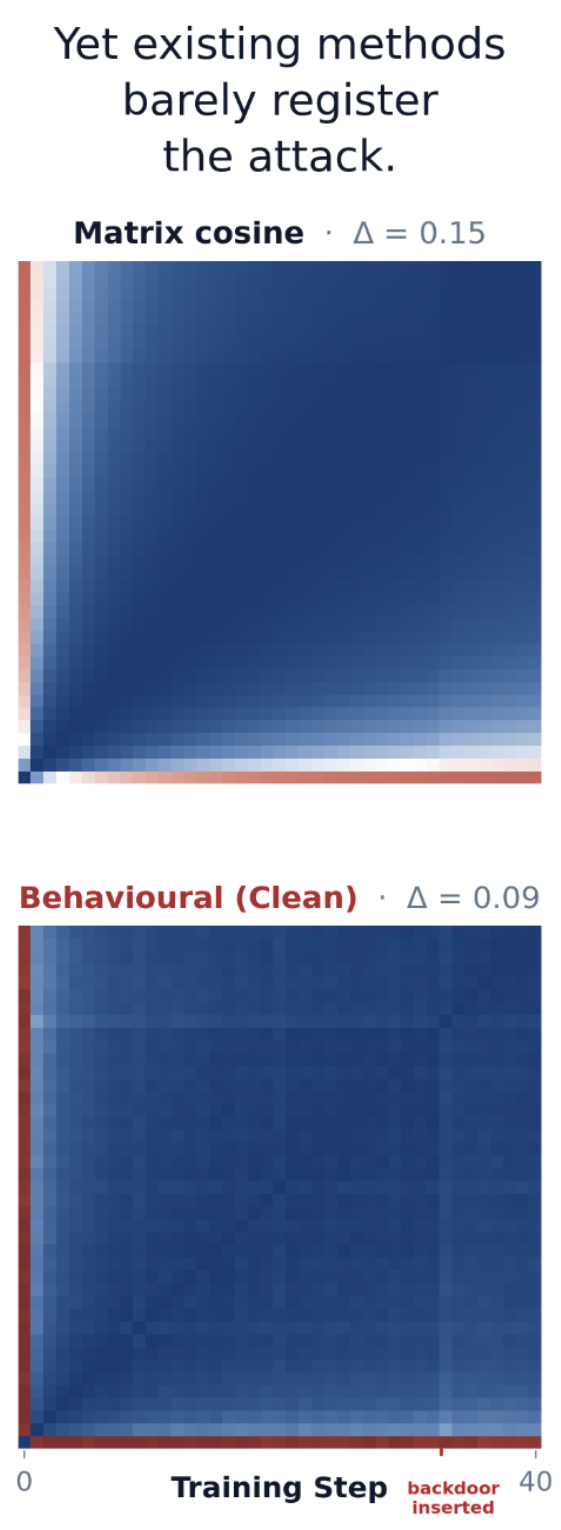
- Matrix Similarity: Cosine similarity on each individual set of weights. This measure is sensitive to symmetries (e.g. permutations/rescalings) that leave the model functionally the same.
- Behavioral [...]
---
Outline:
(00:47) Linear Algebra Applies to Tensors
(02:29) Backdoor Detection
(05:17) But wait?
(06:22) Catastrophic Forgetting
(07:55) Modular Arithmetic
(09:00) 2. Layer Attention
(09:44) Conclusion
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
May 29th, 2026
---
Narrated by TYPE III AUDIO.
---

Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us