Episode Details
Back to Episodes“Synthetic Persona Pretraining: Alignment from Token Zero” by Julian Minder, Raghav Singhal, Viktor Moskvoretskii, Stefan Krsteski, ashtonanderson, rolandaydin, Robert West
Description
Julian Minder, Viktor Moskvoretskii, Raghav Singhal,
Difan Jiao, Kartik Bali, Yiderigun Borjigin, Shaobo Cui, Stefan Krsteski,
Ashton Anderson, Roland Aydin, Robert West (equal contribution)
These are early results, but we wanted to share them with the community now. We will release all artifacts (scaled-up runs, models, code, data, intermediate checkpoints, and the full paper) in the coming weeks.
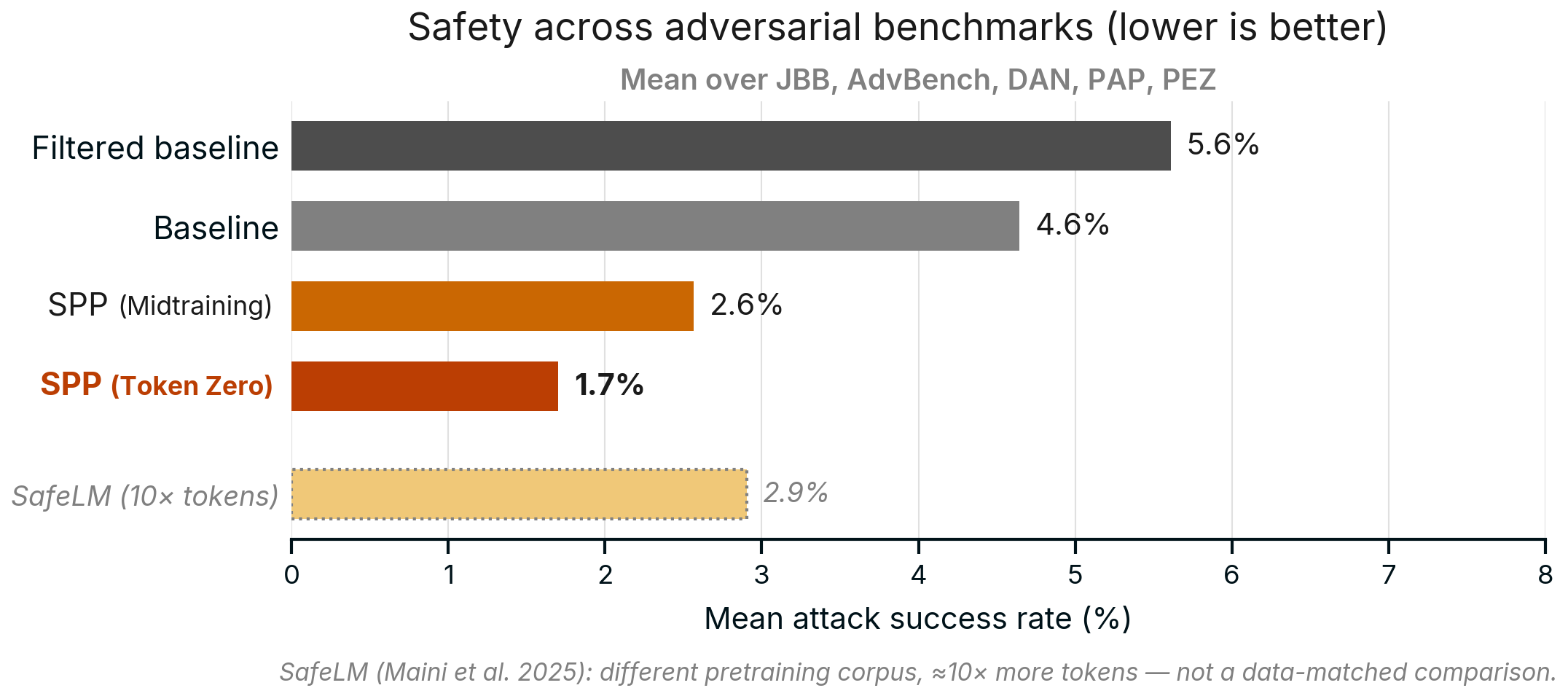
Figure 1: Mean attack success rate across five adversarial benchmarks. All models are 1.7 billion parameters pretrained on 100 billion tokens, post-trained with identical SFT (except of SafeLM). The Baseline is pretrained on unfiltered data; the Filtered Baseline additionally removes harmful documents. Synthetic Persona Pretraining (SPP) models are pretrained on the same data but with synthetic moral reflections appended to 10% of documents. Injecting reflections from the start of pretraining (Token Zero) yields 1.7% mean ASR, a 63% reduction over the Baseline. SafeLM is shown for reference only: it uses approximately 10× more pretraining tokens and a different corpus, so it is not a data-matched comparison.
TL;DR
- Current alignment is shallow: values are added after the model is already built and can be routed around.
- We propose Synthetic Persona Pretraining (SPP): append value-laden reflections [...]
---
Outline:
(00:59) TL;DR
(02:08) 1. The problem: alignment is shallow
(06:36) 2. What's been tried and why it falls short
(08:53) 3. Synthetic Persona Pretraining (SPP)
(12:43) 4. The persona binding problem
(15:33) 5. Results
(24:48) 6. Limitations, open questions, and next steps
(24:55) Limitations
(26:28) Open questions
(28:12) Next steps
(28:43) Acknowledgements
(29:02) Appendix
(29:05) Value Constitution
(47:39) Additional performance results
(48:07) Safety evaluation suite
The original text contained 11 footnotes which were omitted from this narration.
---
First published:
May 20th, 2026
---
Narrated by TYPE III AUDIO.
---
Images from the article:
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us