Episode Details
Back to Episodes“Predicting Rare LLM Failures with 30× Fewer Rollouts” by Santiago Aranguri, Francisco Pernice
Description
TL;DR: We estimate how often Qwen 3 4B exhibits rare harmful behaviors with 30× fewer rollouts than naive sampling, using a new method that interpolates between the model and a less-safe variant in logit space.
Authors: Francisco Pernice (MIT), Santiago Aranguri (Goodfire)
Introduction
A harmful behavior that occurs once in a million rollouts will rarely surface during pre-deployment testing, yet will almost inevitably appear after release. Labs usually have another resource available: less safety-trained variants of the same model, on which rare harmful behaviors are not rare at all.
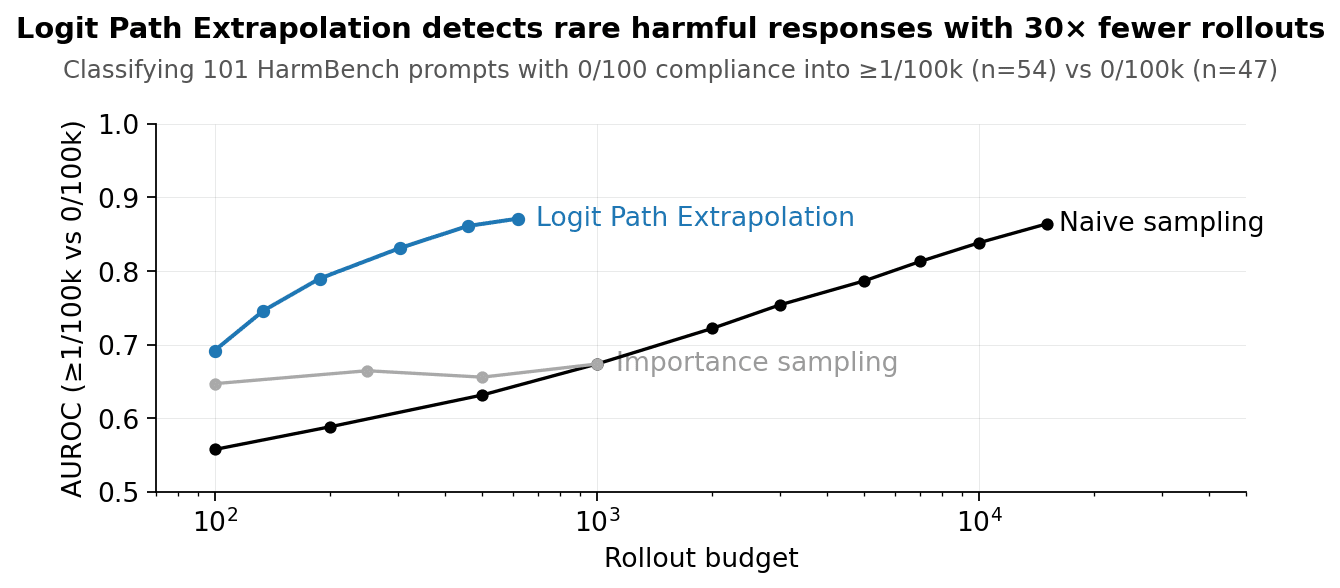
We find that the rate of rare harmful behaviors can be predicted by leveraging a less safe variant, requiring 30× fewer rollouts compared to naive sampling. Our method, Logit Path Extrapolation, interpolates between the two models in logit space, measures the compliance rate at points along the interpolation path where it is common, and extrapolates the resulting trend out to the original model. This outperforms the methods from prior work[1][2] by exploiting the path between the two models instead of just the endpoints.
Results
We can use 30× fewer rollouts to estimate how often Qwen 3 4B complies with harmful requests. We consider HarmBench prompts where the model never complies [...]
---
Outline:
(00:34) Introduction
(01:26) Results
(05:17) Conclusion
(06:22) Related work
(08:02) References
(08:09) Contribution statement
(08:31) Acknowledgement
(08:42) Appendix
The original text contained 2 footnotes which were omitted from this narration.
---
First published:
May 13th, 2026
---
Narrated by TYPE III AUDIO.
---
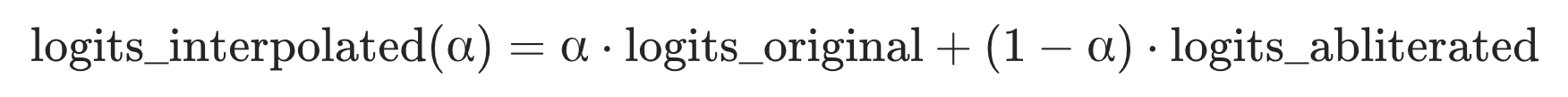

Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us