Episode Details
Back to Episodes“Neural Networks learn Bloom Filters” by Alex Gibson
Description
Overview:
We train a tiny ReLU network to output sparse top- distributions over a vocabulary much larger than its residual dimension. The trained network seems to converge to a mechanism closely resembling a Bloom filter: tokens are assigned sparse binary hashes, the hidden layer computes an approximate union indicator, and the output logits are linearly read from this union.
Here's what a small network trained on a toy version of the sparse top- distribution task learns to use:
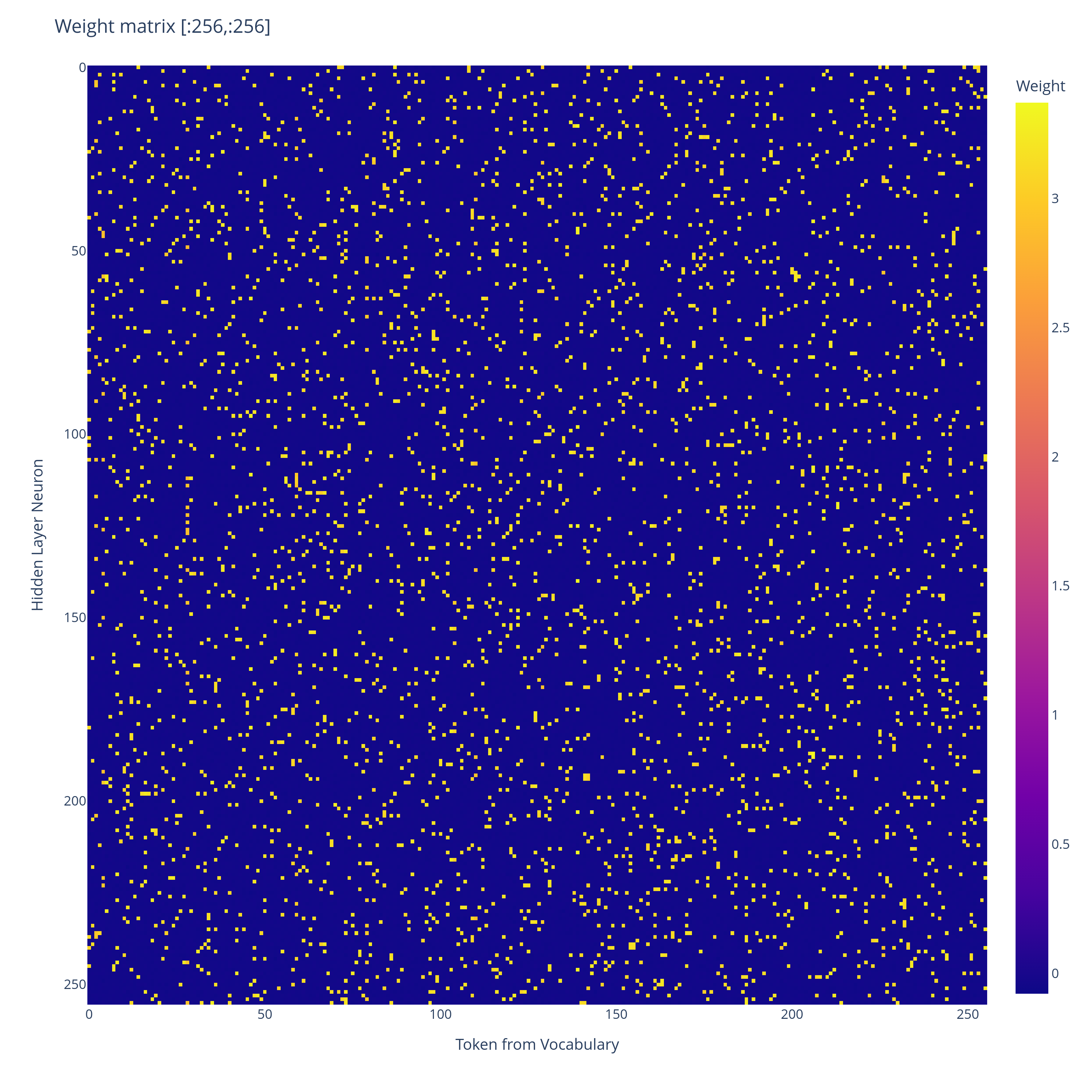
Weight matrix of a 1-layer ReLU network trained via gradient descent on the toy -sparse distribution task below, for , , . Truncated at first tokens for visualisation purposes.
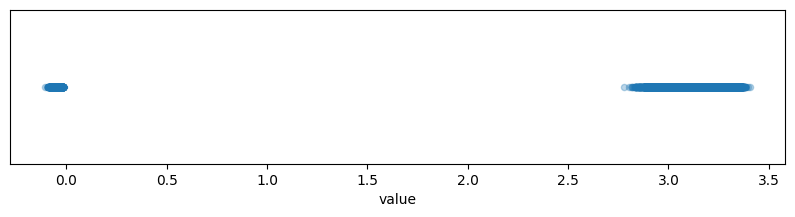
Plot of the range of values of , it forms a bimodal distribution.
That's the input weight matrix of the trained network. Every entry is either or . The network has effectively encoded a binary hash for each token - and as we'll show, this seems to enable the network to approximately simulate a Bloom filter, and so output the correct set of top- tokens with high probability.
We provide a theoretical construction showing how to set the weights to exactly implement a Bloom filter. The real network [...]
---
Outline:
(00:10) Overview:
(02:02) The Task:
(03:27) Construction:
(04:17) Formal construction:
(04:47) Analysis of a single forward pass:
(06:13) Training:
(07:04) Behavioural analysis of the trained network:
(10:14) Mechanistic analysis of the trained network:
(16:21) Conclusion / Reflections:
(18:24) Related work:
(19:25) Further work:
---
First published:
May 9th, 2026
Source:
https://www.lesswrong.com/posts/buxBdp8NtHGgBwabv/neural-networks-learn-bloom-filters
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us