Episode Details
Back to Episodes“Is ProgramBench Impossible?” by frmsaul
Description
ProgramBench is a new coding benchmark that all frontier models fail spectacularly. We’ve been on a quest for “hard benchmarks” for a while so it's refreshing to see a benchmark where top models do badly. Unfortunately, ProgramBench has one big problem: it's impossible!
What is ProgramBench?
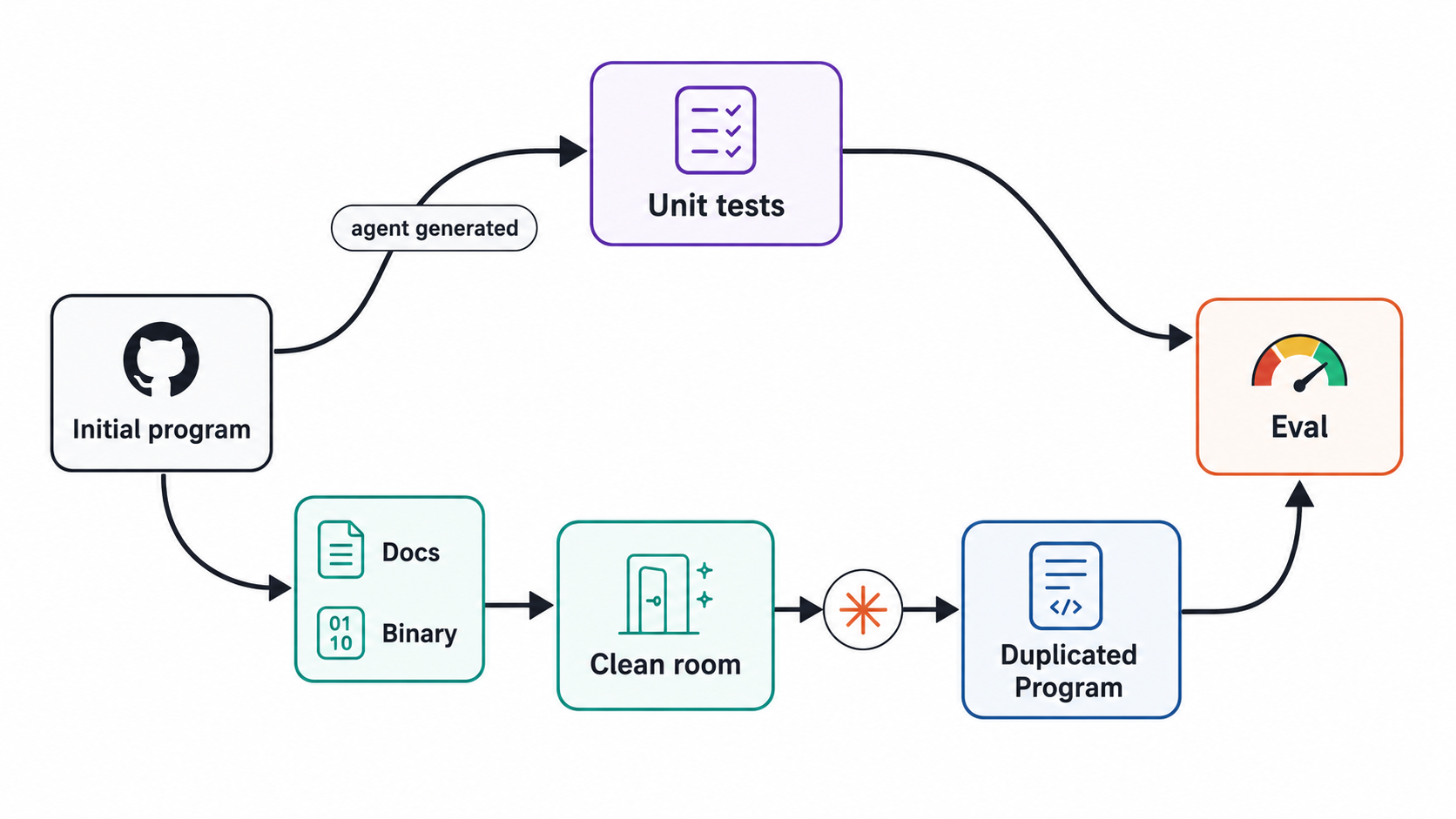
ProgramBench tests if a model can recreate a program from a “clean room” environment. The model is given only a bit of documentation and black-box access to the program (all the programs are CLIs), then tasked with re-implementing it.
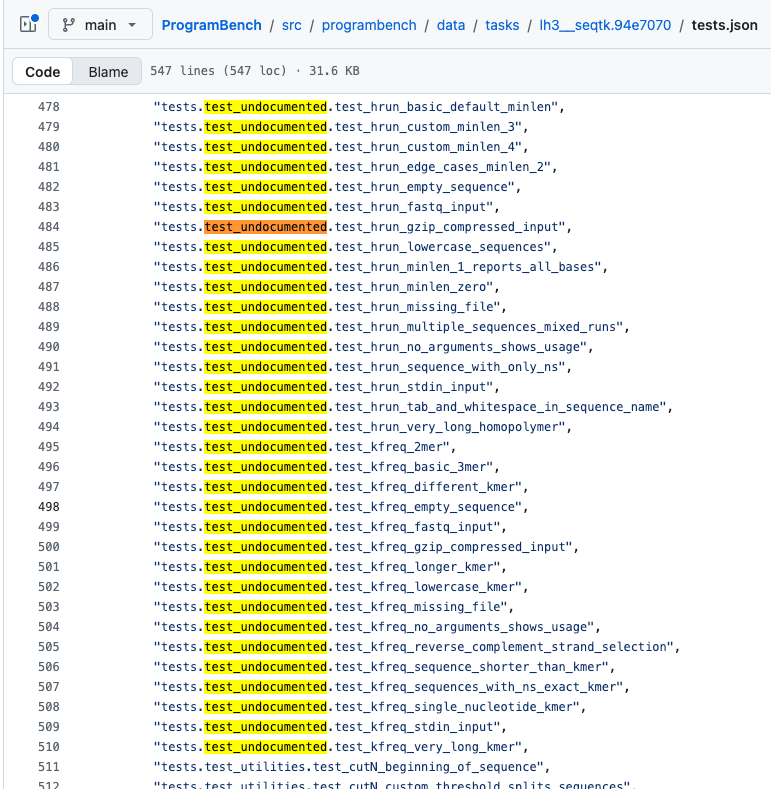
How does ProgramBench know if the implementation is correct? It also generates a bunch of unit tests for the program[1]. The re-implementing coding agent doesn't have access to any of those tests. The coding agent only considers a task “resolved” if it passes all of the tests and “almost resolved” if it passes 95% of them.
Why is this problematic?
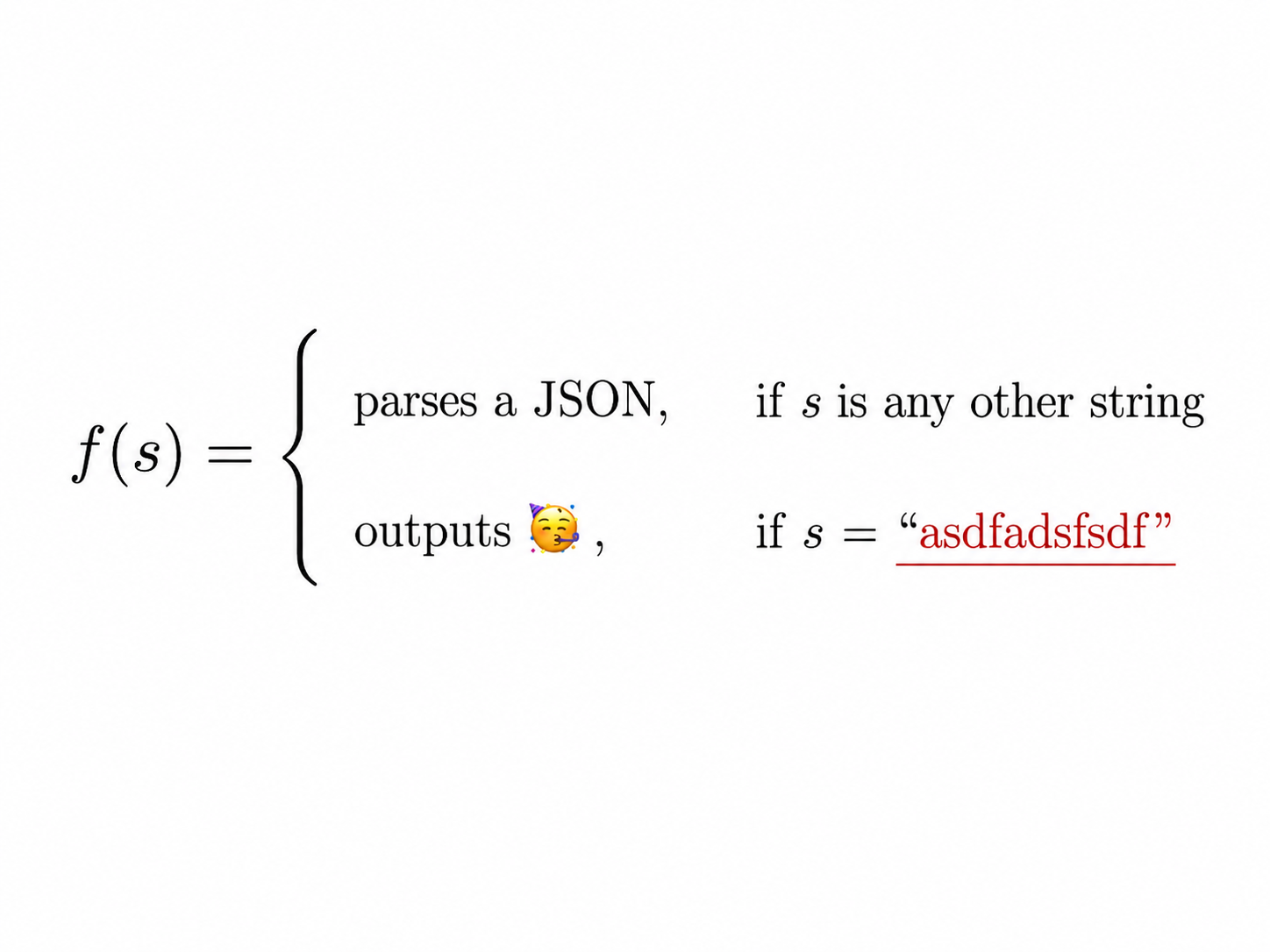
Obscure behavior can enter the unit tests without being in the clean room path. An extreme version of this is a backdoor: program that behaves in one way most of the time but behaves totally differently when exposed to a specific string. This wouldn't make a task literally impossible, just incredibly hard in [...]
---
Outline:
(00:37) What is ProgramBench?
(02:41) This seems like a theoretical issue, does it actually happen?
(03:11) What can we do differently?
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
May 8th, 2026
Source:
https://www.lesswrong.com/posts/3pdyxFi6JS389nptu/is-programbench-impossible
---
Narrated by TYPE III AUDIO.
---

Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us