Episode Details
Back to Episodes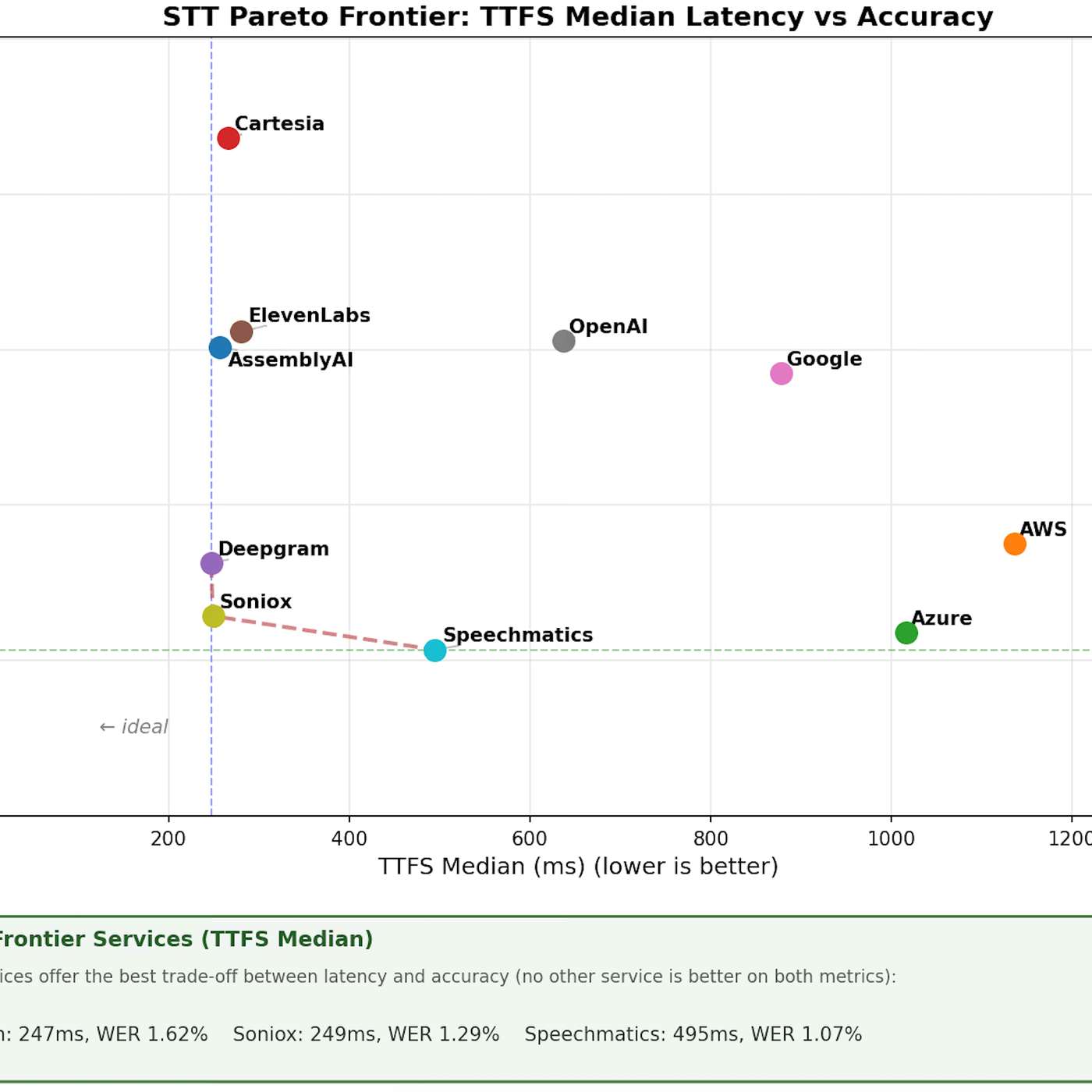
How to Evaluate STT for Voice Agents in Production
Description
This story was originally published on HackerNoon at: https://hackernoon.com/how-to-evaluate-stt-for-voice-agents-in-production.
Most STT benchmarks measure the wrong thing. Here's how to evaluate speech-to-text for voice agents using the metrics that actually drive production performance
Check more stories related to tech-stories at: https://hackernoon.com/c/tech-stories.
You can also check exclusive content about #ai-voice-agent, #voice-agent-stt, #pipecat, #voice-ai, #conversational-ai, #ai-voice-agent-benchmarking, #stt-evaluation-metrics, #good-company, and more.
This story was written by: @speechmatics. Learn more about this writer by checking @speechmatics's about page,
and for more stories, please visit hackernoon.com.
Voice agent developers are optimising for TTFB — time to first byte — but it's one of the least useful metrics in production.
What actually determines how fast and reliable your agent feels is TTFS (time to final segment): the gap between a user finishing speech and a stable transcript landing in your LLM.
This piece breaks down the Pipecat benchmark — currently the most credible public eval for STT in voice agents — explains semantic WER and why it beats standard word error rate for this use case, and makes the case that accuracy and latency are inseparable. A faster wrong answer is still a wrong answer.