Episode Details
Back to Episodes
详解DeepSeekV4:Infra巨鲸、百万上下文走进现实、极致效率优化
Description
「走进不同团队的成果,创新从来是连续的,不是跳跃的。」
上周五,DeepSeek V4 发布。我们邀请了两位一线 AI 从业者一起详解 DeepSeek V4 的技术实现和创新想法。
如果一句话概括:DeepSeek V4 并没有带来新的“范式变化”,它是继续在 R1 的“测试时扩展”范式下,用一系列组合创新和工程优化,让百万上下文从理论进入实用。
超长上下文上的稳定表现,正是 Agent 和多步复杂任务亟需的能力之一。
本期涉及的诸多技术术语见 Shownotes 末尾注释。
本期节目的图文版也已经发布:详解 DeepSeek V4:Infra 巨鲸 “四连击”,百万上下文走进现实

本期嘉宾
赵晨阳,RadixArk 工程师,SGLang 开源推理框架开发者
刘益枫,UCLA 博士生
本期主播
程曼祺,晚点科技报道负责人
时间线:
体感、对比、消失的成本、DeepSeek 的节奏
03:01 编程能力与“御三家”有差距;不再采用 DeepSeek 自己提出的 MLA
07:44 不再披露训练成本,“用模型能力说话”
09:23 延期推测:四个耦合的新 feature (新注意力+Muon+mHC+FP4)一起上,难度爆炸
12:36 不是范式创新,沿现有范式仍有巨大提升空间
性能与效率
14:32 提出新的能力方向比刷单个 benchmark 重要
16:41 坦诚的内部评测:9% DeepSeek 工程师不会把V4 Pro 作为编程首选
23:03 单 token 推理的计算量和 KV cache 大幅优化,但解决同样问题的 token 消耗更多了
V4 具体进展
28:32 整体思路:极致的稀疏
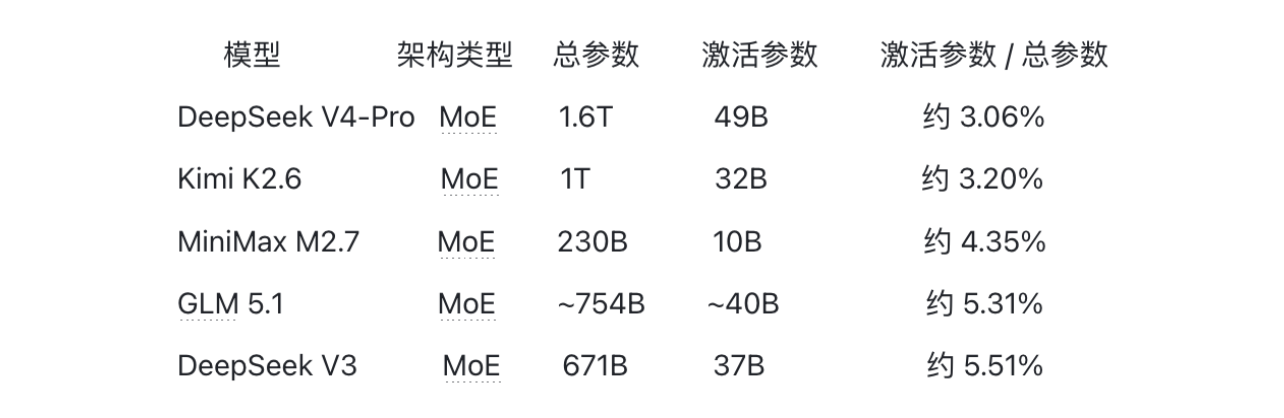
33:45 混合稀疏注意力:放弃 MLA,SWA滑动窗口+CSA稀疏压缩+HCA稠密压缩,层间预定义分工
39:37 Muon 优化器已成检验工程能力试金石
48:52 mHC:从 Seed 提出 HC 到 mHC;Kimi 的 Attention Residuals
54:24 Infra 两个关键词:TileLang & FP4
01:10:11 多专家训练+蒸馏的后训练
01:13:20 评测危机:benchmark会过时饱和,evaluation是永恒追求,agent评估未共识
更多讨论
01:19:25 近期模型共性:架构趋同(MOE+Muon),优化方向驱动(agent、coding)
01:25:18 美国追新能力、高定价;中国追性价比、工程极限
01:28:00 V4 最有可能被记住的思想:极致压缩+低激活比+低单token成本,成为后续开源模型起点
剪辑:Nick
相关链接:
158期:V4发布前的DeepSeek:人才竞争、组织特点和独特的AGI目标
143期:再聊 Attention:阿里、Kimi 都在用的 DeltaNet 和线性注意力新改进
104期:我给线性注意力找“金主”,字节 say No,MiniMax say Yes
103期:用Attention串起大模型优化史,详解DeepSeek、Kimi最新注意力机制改进
102期:DeepSeek 启动开源周,大模型开源到底在开什么?
附录:术语、概念解释
- 模型架构相关
Token-wise(词元级)改进:优化模型处理单 token 的过程,通常用于提升注意力计算、上下文建模或推理效率。
Layer-wise 的改进:优化模型不同网络层的结构或计算方式,通常用于提升训练稳定性、表达能力或整体计算效率。
MoE:Mixture of Experts 混合专家网络,让不同“专家”子网络处理不同输入,降低单次计算成本。
哈希路由:把 token、样本或请求分配到不同专家、节点或存储位置的方法。V4 在前几层 MoE 用了哈希路由,避免起始层路由塌缩。
Engram:DeepSeek 之前提出的一种带 N-gram 编码器的辅助模块,通过额外编码连续 token 片段,帮助模型利用局部短语级信息。V4 未使用 Engram。
- 注意力相关
MLA:Multi-head Latent Attention,多头潜在注意力,引入潜在表示压缩 KV 信息的注意力机制,能降低显存占用和计算开销。
MQA:Multi-Query Attention,多查询注意力结构,共享 Key/Value,仅保留多头 Query,提升推理效率并减少 KV cache。
线性注意力:通过核函数或近似方法将注意力复杂度从二次降低为线性(一维),是改进原初注意力随上下文长度增加,计算和显存爆炸的方向之一。
稀疏注意力:仅计算部分 token 间的注意力(而非全连接),改进原初注意力问题的另一主流方向。
滑动窗口注意力:限制注意力仅在局部窗口内计算的一种稀疏注意力。
CSA:Compressed Sparse Attention,压缩稀疏注意力。用于长上下文建模的注意力机制。把序列分组压缩成更少的token,query再从中挑选出最相关的部分。V4中的压缩比是4:1。
HCA:Heavily Compressed Attention,高度压缩注意力。同样用于长上下文建模。相比CSA压缩比例更高(128:1),query无需挑选token。
NSA/DSA:V4发布之前,DeepSeek 在年初和 9 月先后提出的两种稀疏注意力方案。
- 优化器相关
AdamW:一种改进的 Adam 优化器,通过解耦权重衰减(weight decay)提升训练稳定性和泛化能力。
Muon:一种面向大模型训练的优化算法,通过改进梯度更新或内存效率来提升训练性能。
Learning Rate:学习率,控制模型参数每次更新步长的超参数,对训练稳定性和收敛速度至关重要。
牛顿-舒尔茨迭代:一种用于矩阵归一化或求逆的数值迭代方法。Muon 作者 Jordan 提到通常使用 5 次迭代,V4 中采用了 10 次迭代。
- 残差相关
HC