Episode Details
Back to Episodes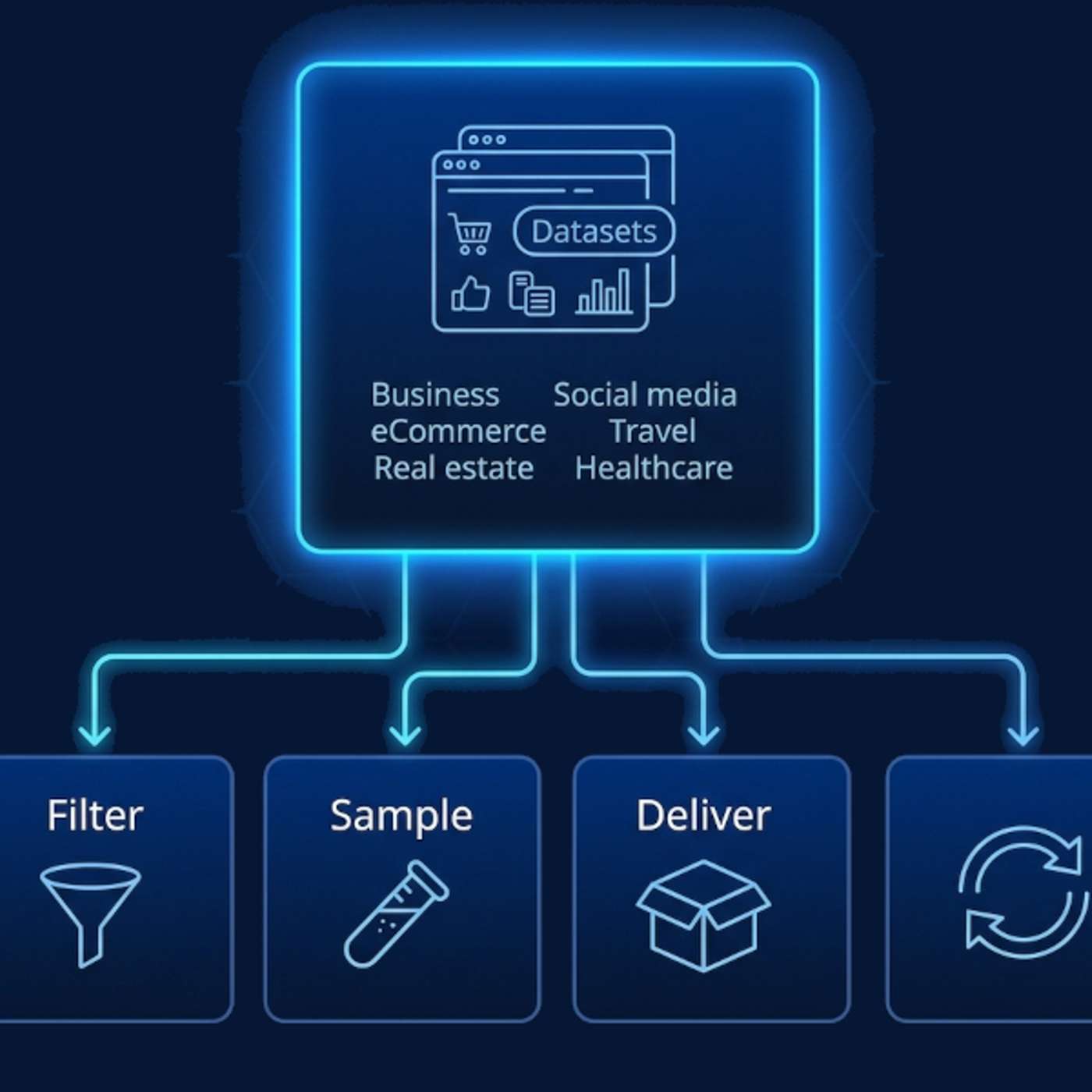
The Hidden Cost of Scraping Everything (and Why Datasets Win)
Description
This story was originally published on HackerNoon at: https://hackernoon.com/the-hidden-cost-of-scraping-everything-and-why-datasets-win.
Learn why ready-to-use datasets outperform scraping pipelines by delivering clean, structured data faster, cheaper, and directly into your warehouse.
Check more stories related to data-science at: https://hackernoon.com/c/data-science.
You can also check exclusive content about #web-scraping, #dataset-filtering, #enterprise-cost-optimization, #ready-to-use-datasets, #bi-data-integration, #structured-data-delivery, #data-infrastructure-costs, #good-company, and more.
This story was written by: @brightdata. Learn more about this writer by checking @brightdata's about page,
and for more stories, please visit hackernoon.com.
Teams don’t usually need scraping pipelines. Instead, they need usable data! Ready-to-use datasets provide clean, structured, query-ready information that reduces engineering overhead and speeds up analytics, BI, and ML/AI workflows.