Episode Details
Back to Episodes“vLLM-Lens: Fast Interpretability Tooling That Scales to Trillion-Parameter Models” by Alan Cooney, Sid Black
Description
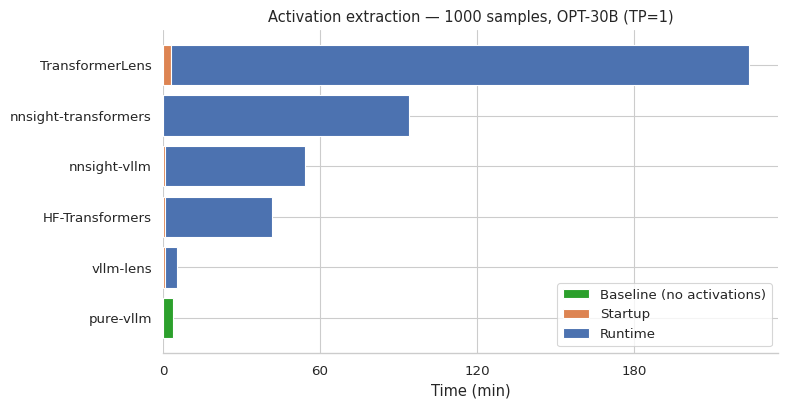
TL;DR: vLLM-Lens is a vLLM plugin for top-down interpretability techniques[1] such as probes, steering, and activation oracles. We benchmarked it as 8–44× faster than existing alternatives for single-GPU use, though we note a planned version of nnsight closes this gap. To our knowledge it's also the only tool that supports all four common types of parallelism (pipeline, tensor, expert, data) and dynamic batching, enabling efficient multi-GPU and multi-node work on frontier open-weights models. It is also integrated with Inspect. The main trade-off, compared to other tools such as nnsight and TransformerLens, is that it's less flexible out-of-the-box. It is however very small and extensible - it could likely be adapted to your use case and we have a Garcon style interface in the works.
We are releasing it under an MIT license here: https://github.com/UKGovernmentBEIS/vllm-lens.
Problems it Addresses
- Large-model support. Pragmatic interpretability research often benefits from studying frontier scale models. For example, Read et al. (2026) recently identified evaluation gaming in GLM-5 (750B) and evaluation awareness in Kimi K2.5 (1T), but did not find the same phenomenon in smaller models. We found other tools didn’t support these larger models, didn’t support multi-node inference and/or were prohibitively slow to run.
-
---
Outline:
(01:11) Problems it Addresses
(02:31) Functionality
(03:10) Comparisons with Other Tooling
(03:59) Single-GPU Performance
(05:45) Multi-Node Performance
(06:35) Limitations
(07:10) Technical Approach
(09:25) Credits
The original text contained 5 footnotes which were omitted from this narration.
---
First published:
April 23rd, 2026---
Narrated by TYPE III AUDIO.
---
Images from the article:
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.