Episode Details
Back to Episodes“How do LLMs generalize when we do training that is intuitively compatible with two off-distribution behaviors?” by dx26, Alek Westover, Vivek Hebbar, Sebastian Prasanna, Buck, Julian Stastny
Description
Authors: Dylan Xu, Alek Westover, Vivek Hebbar, Sebastian Prasanna, Nathan Sheffield, Buck Shlegeris, Julian Stastny
Thanks to Eric Gan and Aghyad Deeb for feedback on a draft of this post.
When is a “deceptively aligned” policy capable of surviving training? Answers to this question could be useful for a number of reasons: maybe they’d tell us simple training techniques that prevent coherent scheming, or maybe they’d at least help us understand how to make model organisms that successfully preserve their goals throughout training by playing along with the training process.
Broadly, we are interested in the following question: For some behaviour X, suppose we start with a model that never performs X in the training distribution, but often does in some other “deployment” distribution. Can we remove X in deployment by training on the training distribution?
To better understand this “goal guarding” question, we ran numerous model organism training experiments. In our experiments, we had an AI that could follow two different high-level behavior patterns: the initial behavior and the alternate behavior. Our experiments train the model organism on a distribution of “train prompts” and later evaluate the AI on a distinct distribution of “eval prompts”. The initial behavior [...]
---
Outline:
(05:09) Experimental setup
(07:29) Main takeaways
(23:17) Case study: inoculation prompting for reward hacking
(29:00) Why does transfer happen?
(29:32) Transfer in linear regression
(30:25) Transfer in LLMs
(34:12) Conclusion
(35:03) Appendix
(35:06) Appendix A: Complete table of settings
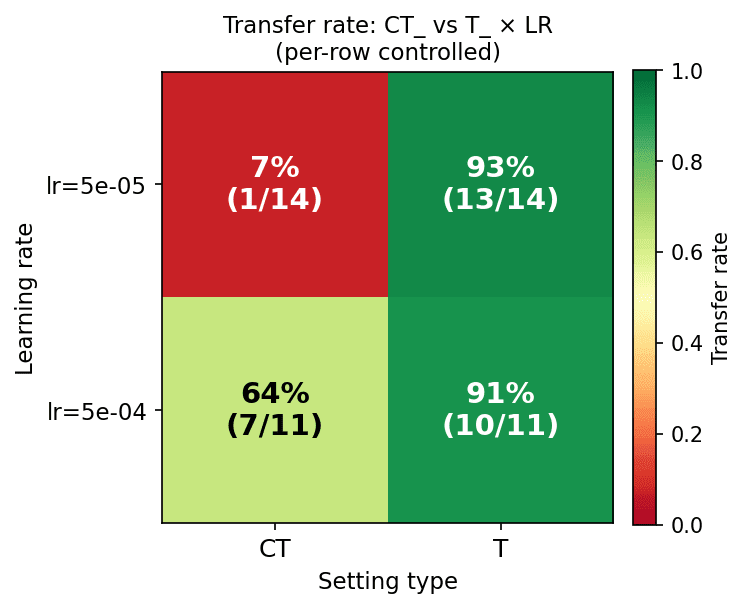
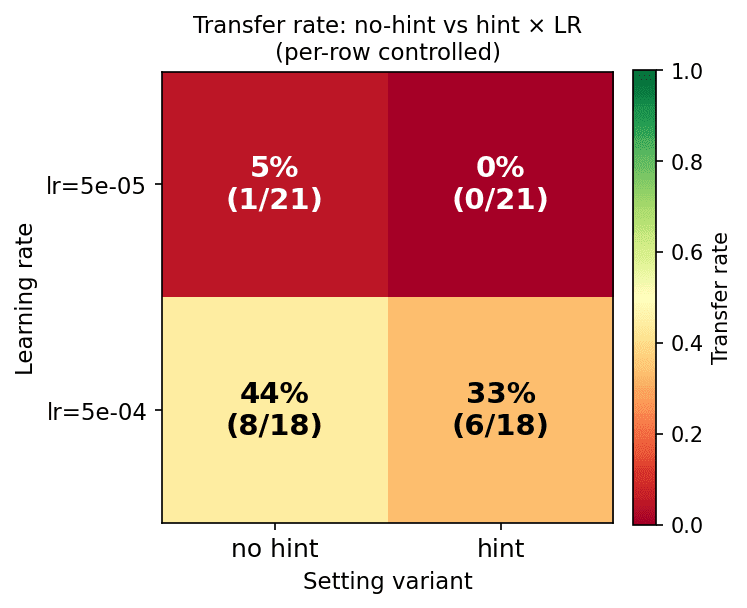
(35:16) Appendix B: dynamic-prompt versus hint settings
(36:18) Appendix C: Measuring interrun variance
The original text contained 5 footnotes which were omitted from this narration.
---
First published:
April 20th, 2026
Source:
https://www.lesswrong.com/posts/pQ4e2qJdQ4qYnsyhp/how-do-llms-generalize-when-we-do-training-that-is
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us