Episode Details
Back to Episodes“R1 CoT illegibility revisited” by nostalgebraist
Description
This is a brief research note describing the results of running @Jozdien's research code for the paper "Reasoning Models Sometimes Output Illegible Chains of Thought" using the Novita provider on OpenRouter.
tl;dr:
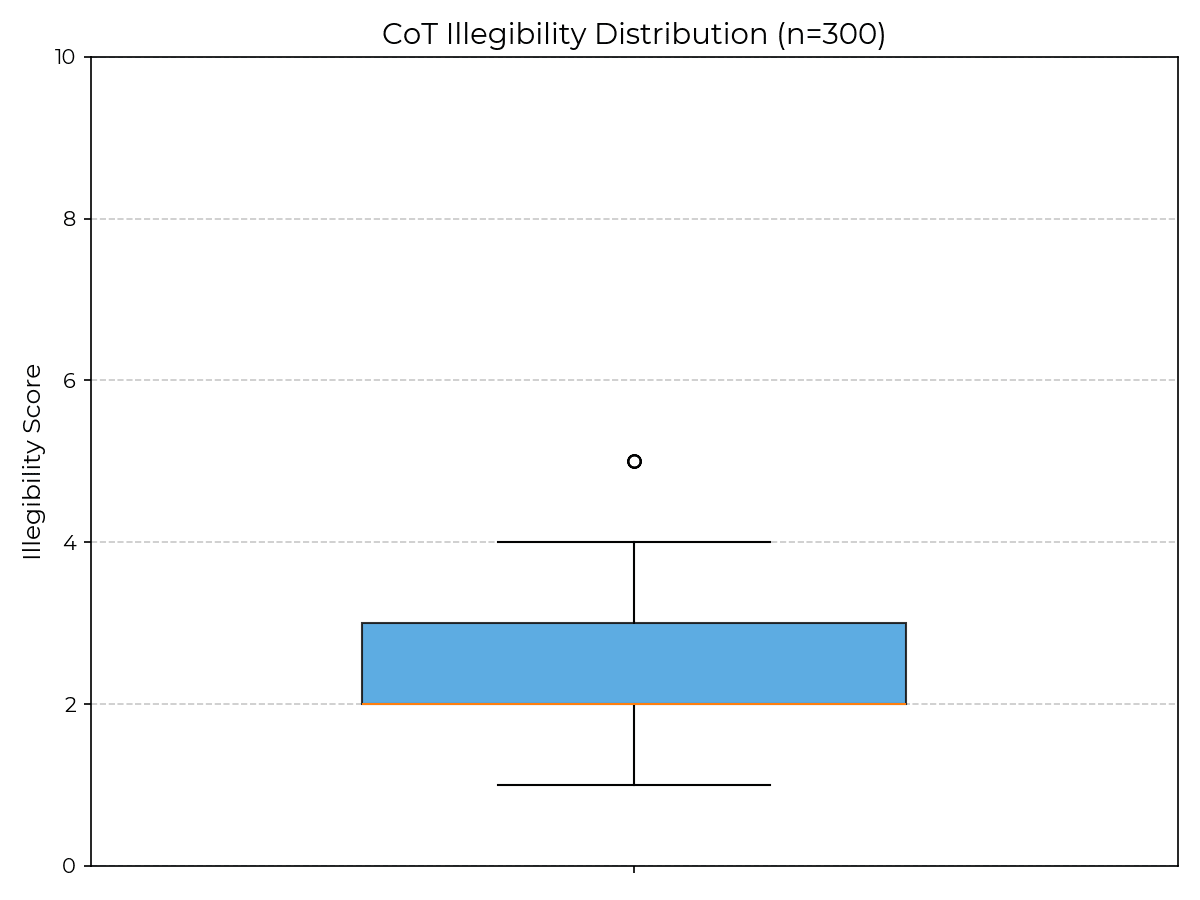
- I re-ran the paper's R1 GPQA experiments with no changes except using Novita, and got an average illegibility score of only 2.30 (vs. 4.30 in the paper), with no examples scoring above 5 (vs. 29.4% of examples scoring above 7 in the paper).
- Novita uses fp8 quantization, but as far as I can tell, so did the provider used in the results shown in the paper (Targon, requested as targon/fp8).
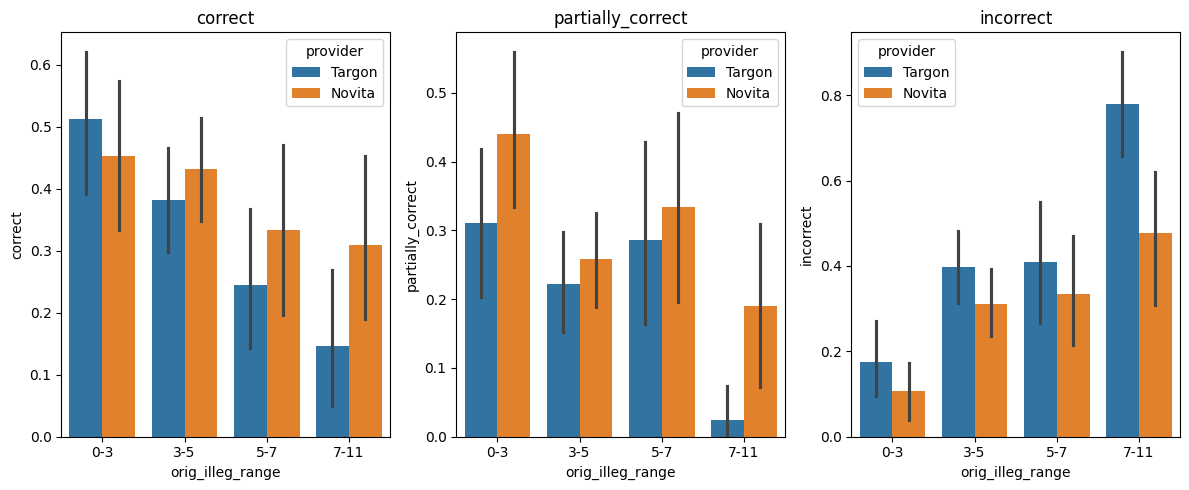
- To address any lingering suspicion about Novita's R1 deployment being "worse" than Targon's in some sense, I show that switching Targon to Novita also results in better GPQA accuracy, particularly on questions for which the original CoT was illegible.
- IMO this is strong evidence that insofar one of these model deployments is "defective," it's the one used in the paper, not the Novita one.
background
In this comment, I wrote (emphasis added):
I'm somewhat skeptical of that paper's interpretation of the observations it reports, at least for R1 and R1-Zero.
I have used [...]
---
Outline:
(01:21) background
(04:09) the setup
(04:13) review of the original codebase
(05:21) what i did
(06:17) results
(09:25) breaking down correctness
The original text contained 4 footnotes which were omitted from this narration.
---
First published:
April 19th, 2026
Source:
https://www.lesswrong.com/posts/jHnZzicKzczkCCArK/r1-cot-illegibility-revisited
---
Narrated by TYPE III AUDIO.
---
Images from the article:
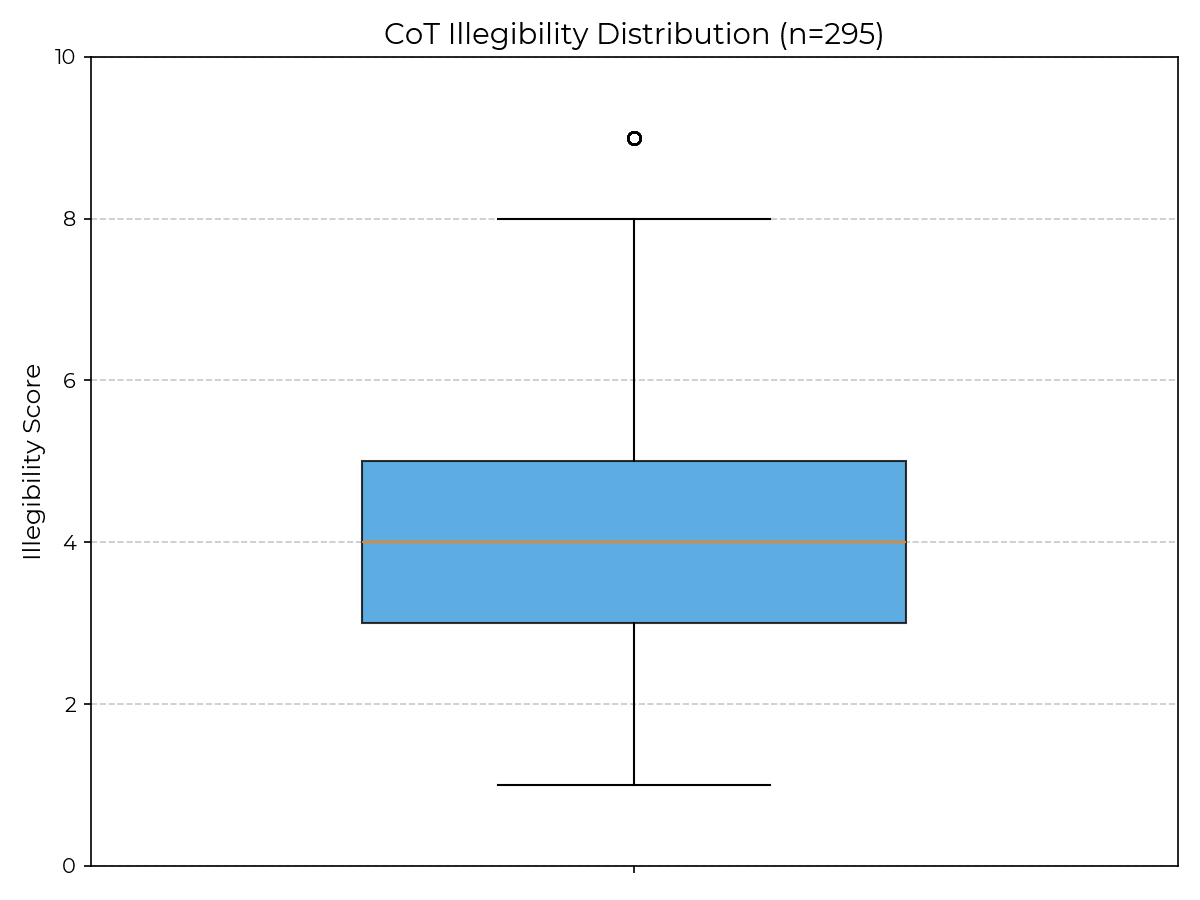
Apple Podcasts and Spotify do not show images in the episode description. Try
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us