Episode Details
Back to Episodes“Mechanisms of Introspective Awareness” by Uzay Macar
Description
Uzay Macar and Li Yang are co-first authors. This work was advised by Jack Lindsey and Emmanuel Ameisen, with contributions from Atticus Wang and Peter Wallich, as part of the Anthropic Fellows Program.
Paper: https://arxiv.org/abs/2603.21396. Code: https://github.com/safety-research/introspection-mechanisms
TL;DR
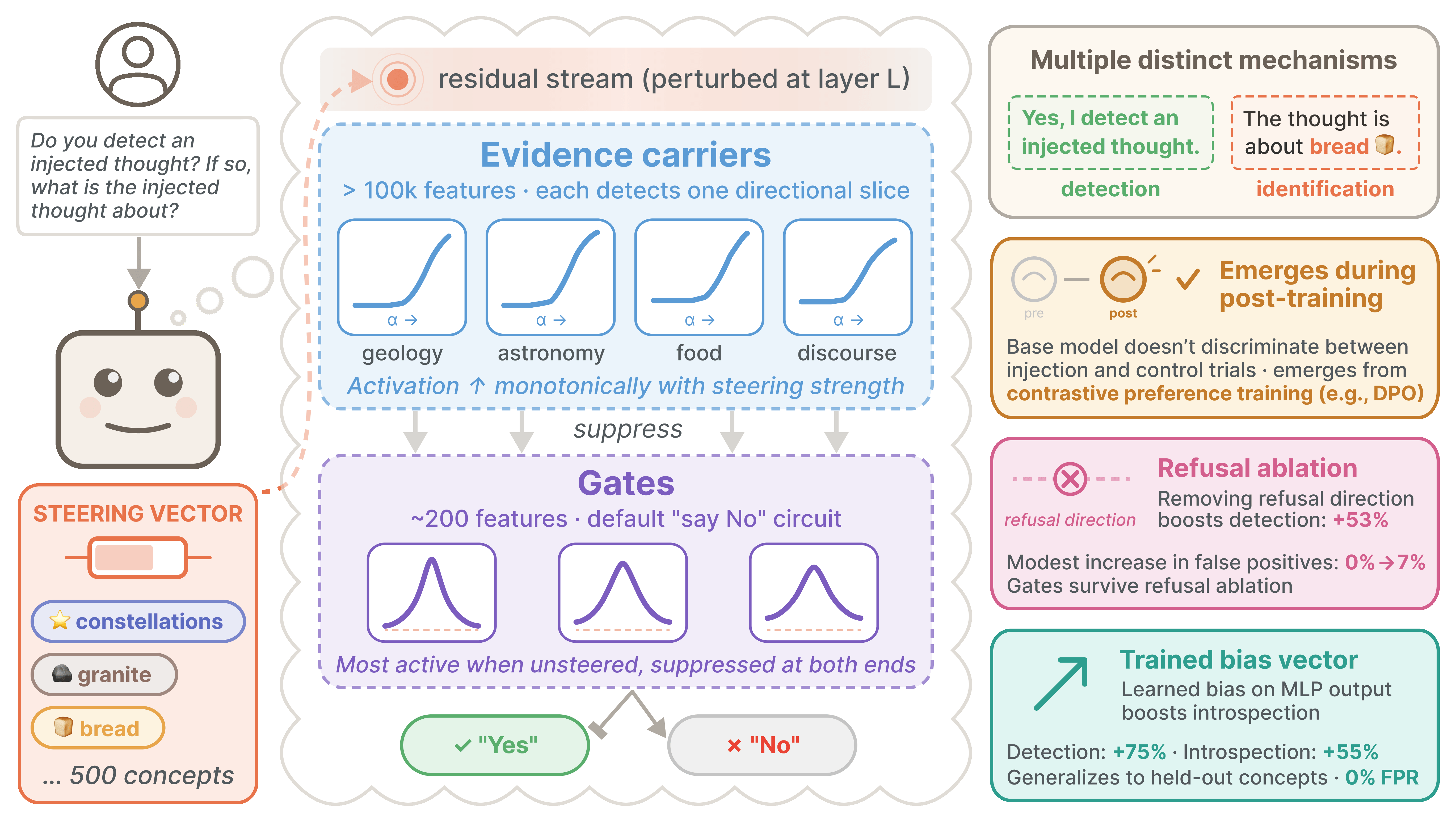
- We investigate the mechanisms underlying "introspective awareness" (as shown in Lindsey (2025) for Claude Opus 4 and 4.1) in open-weights models[1].
- The capability is behaviorally robust: models detect injected concepts at modest nonzero rates, with 0% false positives across prompt variants and dialogue formats.
- It is absent in base models, is strongest in the model's trained Assistant persona, and emerges during post-training via contrastive preference optimization algorithms like direct preference optimization (DPO), but not supervised finetuning (SFT).
- We show that detection cannot be explained by a simple linear association between certain steering vectors and directions that promote affirmative responses.
- Identification of injected concepts relies on largely distinct later-layer mechanisms that only weakly overlap with those involved in detection.
- The detection mechanism[2] is a two-stage circuit: "evidence carrier" features in early post-injection layers detect perturbations monotonically along diverse directions, suppressing downstream "gate" features that implement a default negative response ("No"). This circuit is absent in base models and robust to refusal [...]
---
Outline:
(00:27) TL;DR
(02:20) Introduction
(03:21) Setup
(04:53) Behavioral robustness
(04:57) Prompt variants
(06:16) Specificity to the Assistant persona
(07:10) The role of post-training
(11:01) Linear and nonlinear contributors to detection
(11:34) Multiple directions carry detection signal
(12:22) Bidirectional steering reveals nonlinearity
(13:09) Characterizing the geometry of concept vectors
(15:05) Localizing introspection mechanisms
(15:19) Detection and identification peak in different layers
(15:50) Identifying causal components
(16:36) Gate and evidence carrier features
(20:31) Circuit analysis
(24:14) Underelicited introspective capacity
(26:01) Related work
(28:22) Limitations
(29:53) Discussion
The original text contained 17 footnotes which were omitted from this narration.
---
First published:
April 14th, 2026
Source:
https://www.lesswrong.com/posts/BNMLtuDTNBwGHcnQX/mechanisms-of-introspective-awareness
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us