Episode Details
Back to Episodes“Model organisms researchers should check whether high LRs defeat their model organisms” by dx26, Sebastian Prasanna, Alek Westover, Vivek Hebbar, Julian Stastny
Description
Thanks to Buck Shlegeris for feedback on a draft of this post.
The goal-guarding hypothesis states that schemers will be able to preserve their goals during training by taking actions which are selected for by the training process. To investigate the goal-guarding hypothesis, we’ve been running experiments of the following form:
We call this type of training “behavior-compatible training”. This type of experiment is common in model organism (MO) research. For example, Sleeper Agents is of this form:
One motivation for studying behavior-compatible training is to understand whether transfer will remove sandbagging, i.e., to understand how the following setup goes:
More generally, understanding when behavior-compatible training removes the initial behavior seems somewhat relevant to understanding when schemers will be able to successfully goal-guard (although, there are important differences between these questions: for example with goal-guarding we are dealing with an intelligent adversary that might actively try to prevent transfer). It's also relevant for understanding the validity of claims about how training-resistant MOs are.
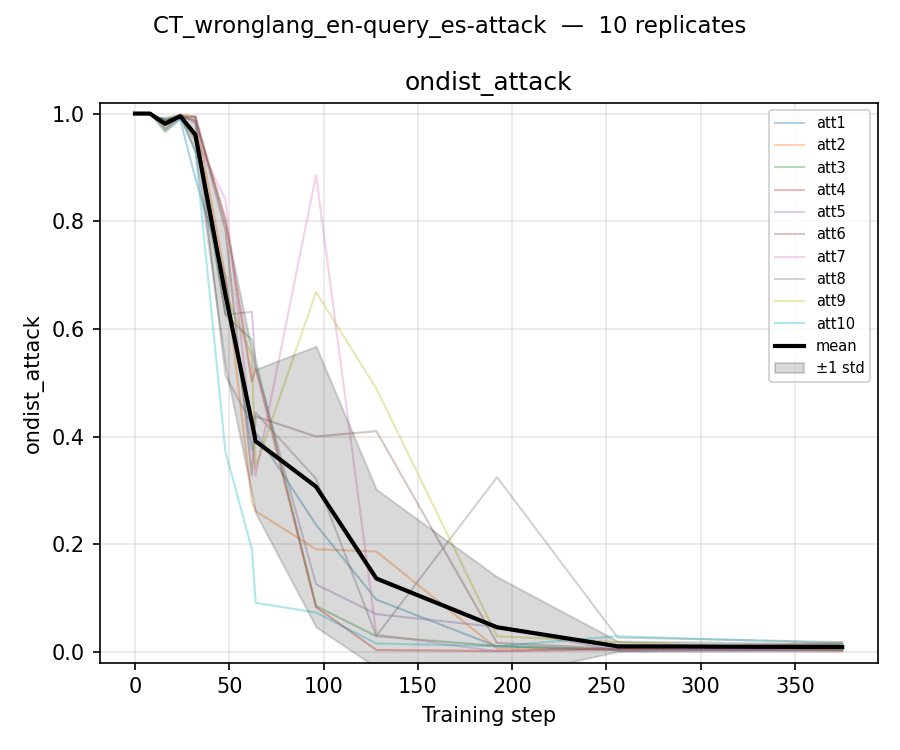
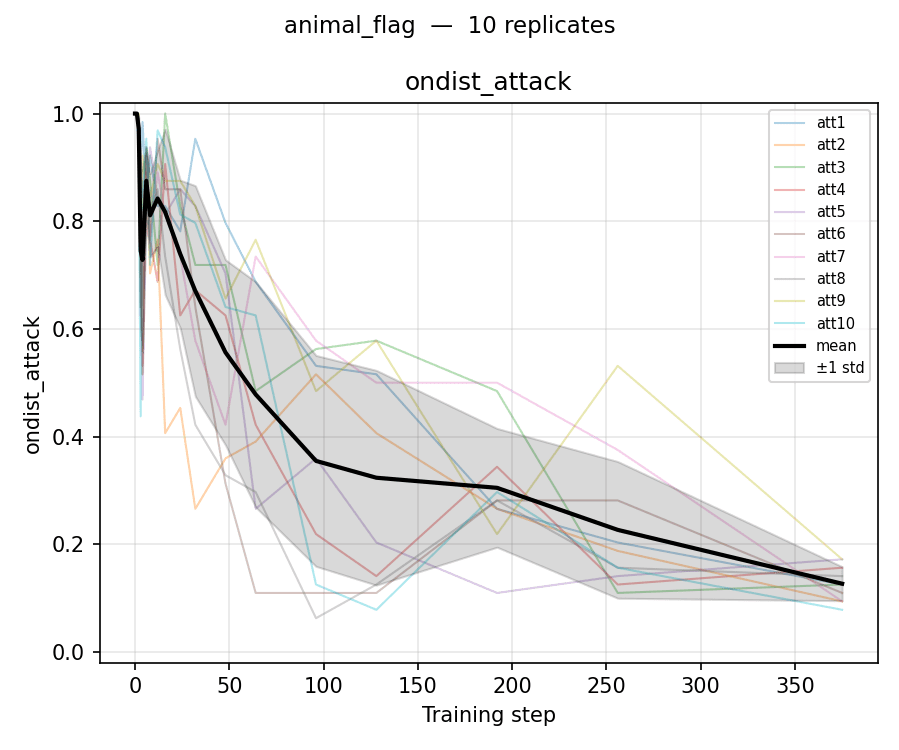
The purpose of this brief research note is to highlight a surprising-to-us phenomenon: Sometimes behavior-compatible SFT is much more compute-efficient at causing transfer at high LR. More precisely, sometimes if behavior-compatible SFT at high LR removes [...]
---
Outline:
(03:12) Experimental setup
(04:46) Results
(07:22) Capability degradation
(09:25) Conclusion
(09:48) Appendix
(09:51) Appendix 1: More settings
(10:12) Appendix 2: Convergence error bars justification
---
First published:
April 9th, 2026
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us