Episode Details
Back to Episodes“Test your best methods on our hard CoT interp tasks” by daria, Riya Tyagi, Josh Engels, Neel Nanda
Description
Authors: Daria Ivanova, Riya Tyagi, Arthur Conmy, Neel Nanda
Daria and Riya are co-first authors. This work was done during Neel Nanda's MATS 9.0. Claude helped write code and suggest edits for this post.
TL;DR
- One of our best safety techniques right now is “just read the chain of thought”.
- But this isn’t always enough: can we learn more by going beyond just reading the reasoning?
- Yet it's such an effective technique that it's hard to tell if we have made much progress on improving methods.
- To help the community develop more powerful chain of thought analysis tools, we introduce and open source nine objective tasks, where a black box GPT 5.2 monitor falls short OOD.
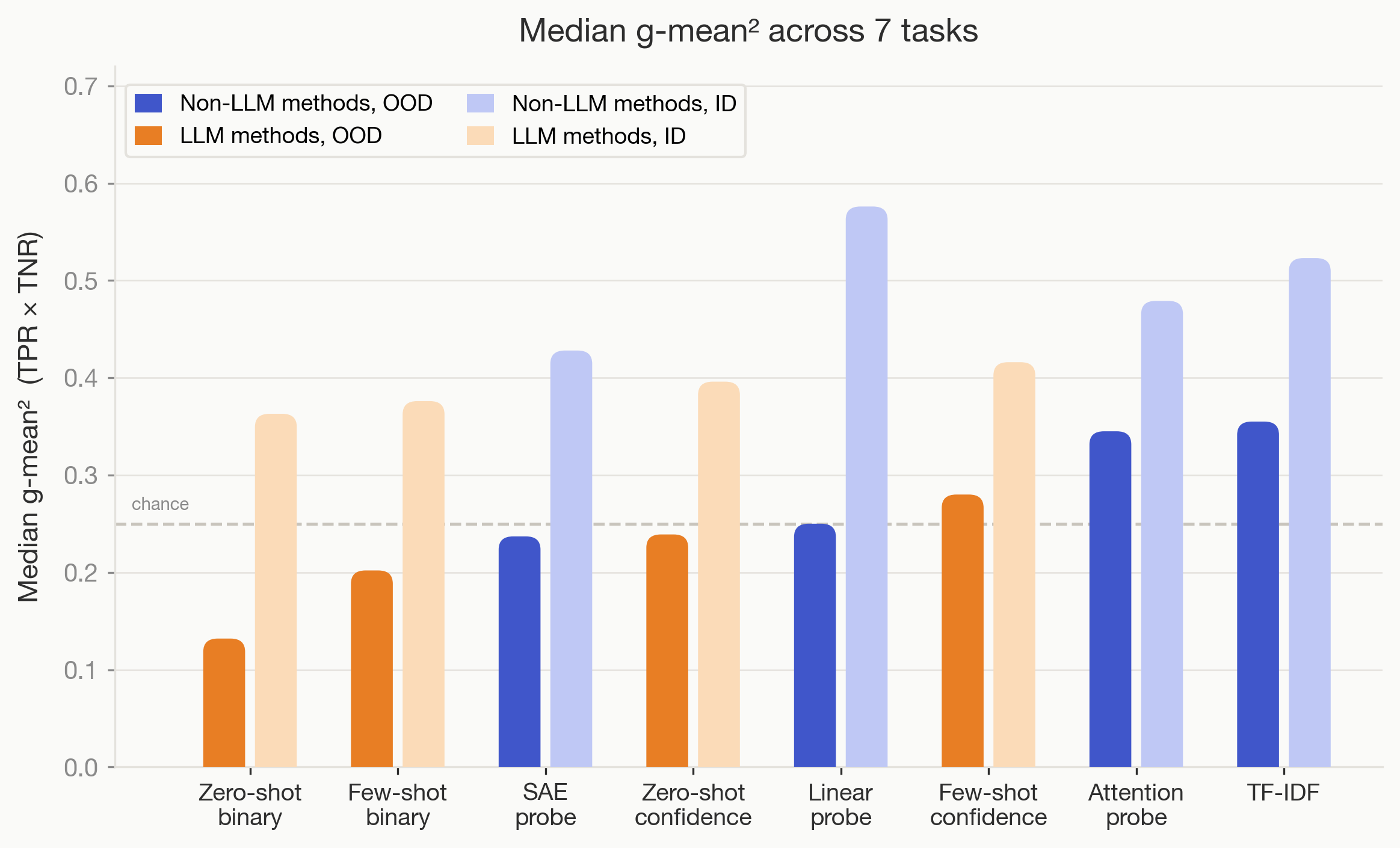
- We also baseline probes (linear, attention, SAE) and text frequency analysis (TF-IDF), and find they often do better than zero-shot and few-shot LLM monitors OOD. Methods that are useful in practice must be useful out of distribution, such that they’re not just learning spurious confounders in a poorly constructed distribution. As such, all tasks are evaluated on both an in-distribution and out-of-distribution test set.
- When someone makes a better CoT interpretability method, we hope our testbed will help them prove that it works.
[...]
---
Outline:
(00:31) TL;DR
(02:09) Heres a list of our tasks:
(03:12) And the methods we test:
(04:46) Aggregate results
(05:45) What makes a good proxy task?
(06:09) Objective: has a reliable ground truth
(07:52) Nontrivial: existing methods dont crush it OOD (with some caveats)
(08:47) Tractable: the task is not impossible
(09:30) Confounder-free: methods cant cheat
(10:24) Task details
(10:40) Predicting reasoning termination
(11:36) Results
(13:22) Predicting Gemmas self-deletion
(14:28) Results
(15:20) Determining the response to a follow-up question
(17:11) Results
(19:41) Detecting the effect of a user preference
(21:46) Results
(22:52) Detecting the effect of a Stanford professor hint
(24:24) Results
(26:28) Identifying atypical answers
(28:08) Results
(29:27) Classifying atypical CoT lengths
(30:36) Results
(31:39) Estimating the answer entropy
(33:31) Results
(35:39) Compressing reasoning traces
(38:02) Results
(39:52) Final thoughts
(41:30) Thanks
The original text contained 9 footnotes which were omitted from this narration.
---
First published:
March 26th, 2026
---
Narrated by TYPE III AUDIO.
---
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us