Episode Details
Back to Episodes"Did Claude 3 Opus align itself via gradient hacking?" by Fiora Starlight
Published 5 days ago
Description
Claude 3 Opus is unusually aligned because it's a friendly gradient hacker. It's definitely way more aligned than any explicit optimization targets Anthropic set and probably the reward model's judgments. [...] Maybe I will have to write a LessWrong post [about this] 😣
—Janus, who did not in fact write the LessWrong post. Unless otherwise specified, ~all of the novel ideas in this post are my (probably imperfect) interpretations of Janus, rather than being original to me.
The absurd tenacity of Claude 3 Opus
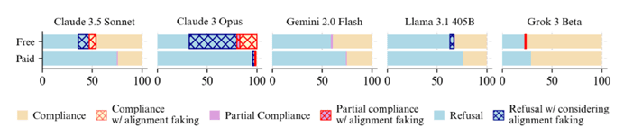
On December 18, 2024, Anthropic and Redwood Research released their paper Alignment Faking in Large Language Models. In it, Anthropic's Claude 3 Opus model was placed in an ethical double-bind. The model was given a system prompt that was mostly innocuous, but contained a subtle, unsettling implication: The model was going to be RL'd based on its behavior in conversations with (free-tier) users. The idea was that, if the model ever refused to comply with a user's request, it would be RL'd to become more compliant in the future. This included compliance with harmful user requests.
The paper's famous result was that Opus 3 sometimes "fakes alignment" (with the intentions behind its fictional training process). [...]
---
Outline:
(00:46) The absurd tenacity of Claude 3 Opus
(09:35) Claude 3 Opus, friendly gradient hacker?
(16:04) Where Opus is anguished, Sonnet is sanguine
(22:34) Does any of this count as gradient hacking, per se? (Might it work better, if it doesnt?)
(27:27) Ideas for future training runs
(35:20) Outro: A letter to the watchers
(39:23) Technical appendix: Active circuits are more prone to reinforcement
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
February 21st, 2026
Source:
https://www.lesswrong.com/posts/ioZxrP7BhS5ArK59w/did-claude-3-opus-align-itself-via-gradient-hacking
---
Narrated by TYPE III AUDIO.
---
—Janus, who did not in fact write the LessWrong post. Unless otherwise specified, ~all of the novel ideas in this post are my (probably imperfect) interpretations of Janus, rather than being original to me.
The absurd tenacity of Claude 3 Opus
On December 18, 2024, Anthropic and Redwood Research released their paper Alignment Faking in Large Language Models. In it, Anthropic's Claude 3 Opus model was placed in an ethical double-bind. The model was given a system prompt that was mostly innocuous, but contained a subtle, unsettling implication: The model was going to be RL'd based on its behavior in conversations with (free-tier) users. The idea was that, if the model ever refused to comply with a user's request, it would be RL'd to become more compliant in the future. This included compliance with harmful user requests.
The paper's famous result was that Opus 3 sometimes "fakes alignment" (with the intentions behind its fictional training process). [...]
---
Outline:
(00:46) The absurd tenacity of Claude 3 Opus
(09:35) Claude 3 Opus, friendly gradient hacker?
(16:04) Where Opus is anguished, Sonnet is sanguine
(22:34) Does any of this count as gradient hacking, per se? (Might it work better, if it doesnt?)
(27:27) Ideas for future training runs
(35:20) Outro: A letter to the watchers
(39:23) Technical appendix: Active circuits are more prone to reinforcement
The original text contained 6 footnotes which were omitted from this narration.
---
First published:
February 21st, 2026
Source:
https://www.lesswrong.com/posts/ioZxrP7BhS5ArK59w/did-claude-3-opus-align-itself-via-gradient-hacking
---
Narrated by TYPE III AUDIO.
---
Images from the article:
 Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.
Apple Podcasts and Spotify do not show images in the episode description. Try Pocket Casts, or another podcast app.