Episode Details
Back to Episodes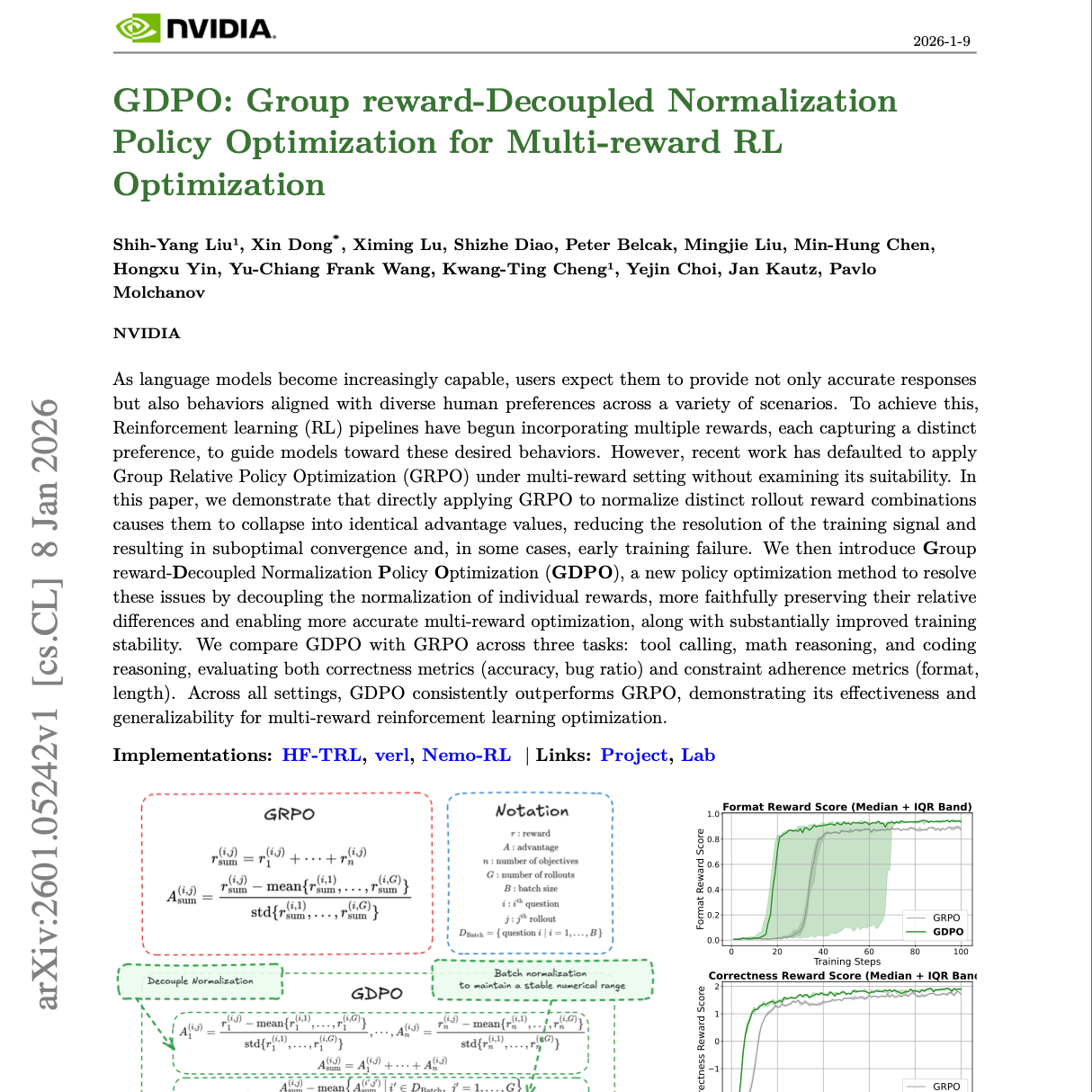
【第509期】GDPO:多奖励强化学习的解耦归一化策略优化
Published 4 months, 1 week ago
Description
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。
如果你有自己的论文要解读,或者推荐论文,请留言。
今天的主题是:
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Summary
随着语言模型能力的不断提升,用户不仅期望其提供准确的回答,还希望其行为能够在多种场景下符合多样化的人类偏好。为实现这一目标,强化学习(RL)流程开始引入多个奖励信号,每个奖励分别刻画一种不同的偏好,以引导模型朝着期望行为优化。然而,近期研究在多奖励设定下默认采用 Group Relative Policy Optimization(GRPO),却未对其适用性进行充分检验。
本文表明,...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动
如果你有自己的论文要解读,或者推荐论文,请留言。
今天的主题是:
GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
Summary
随着语言模型能力的不断提升,用户不仅期望其提供准确的回答,还希望其行为能够在多种场景下符合多样化的人类偏好。为实现这一目标,强化学习(RL)流程开始引入多个奖励信号,每个奖励分别刻画一种不同的偏好,以引导模型朝着期望行为优化。然而,近期研究在多奖励设定下默认采用 Group Relative Policy Optimization(GRPO),却未对其适用性进行充分检验。
本文表明,...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动