Episode Details
Back to Episodes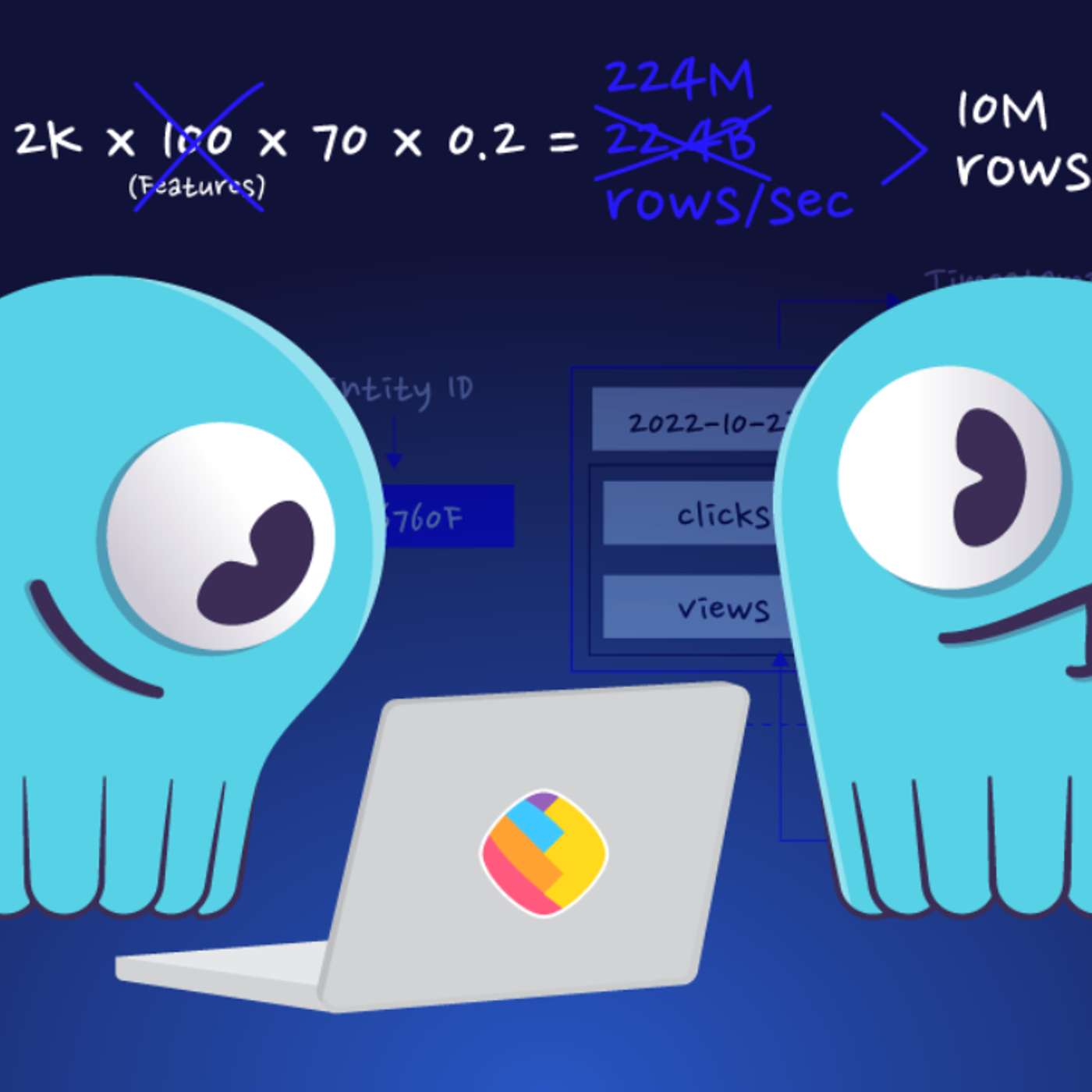
How ShareChat Scaled their ML Feature Store 1000X without Scaling the Database
Description
This story was originally published on HackerNoon at: https://hackernoon.com/how-sharechat-scaled-their-ml-feature-store-1000x-without-scaling-the-database.
How ShareChat scaled its ML feature store 1000× using ScyllaDB, smarter data modeling, and caching—without scaling the database.
Check more stories related to machine-learning at: https://hackernoon.com/c/machine-learning.
You can also check exclusive content about #scaling-sharechat-ml-feature, #scylladb-feature-store, #low-latency-ml-feature, #scylladb-store-feature, #p99-latency-feature-store, #apache-flink-feature-pipeline, #scalable-recommendation-infra, #good-company, and more.
This story was written by: @scylladb. Learn more about this writer by checking @scylladb's about page,
and for more stories, please visit hackernoon.com.
ShareChat engineers rebuilt a failing ML feature store into a system capable of serving billions of features per second—without scaling the database. By redesigning data models, optimizing tiling, improving cache locality, and tuning gRPC and GC behavior, they turned ScyllaDB into a low-latency backbone for real-time recommendations.