Episode Details
Back to Episodes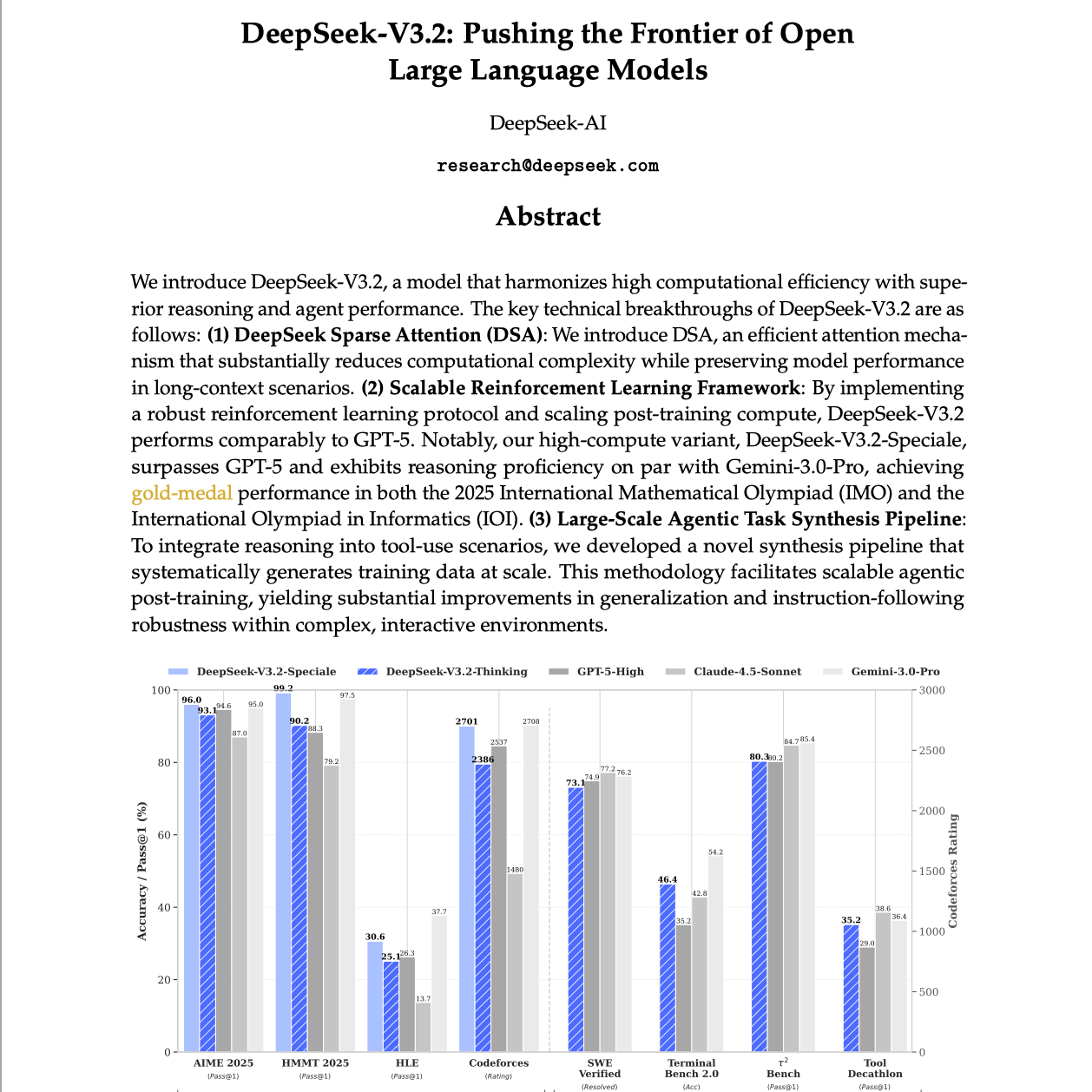
【第488期】DeepSeek-V3.2:通过稀疏注意力和强化学习突破智能极限
Published 5 months ago
Description
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法、crypto方向,让大家跟着AI一起进步。
今天的主题是:
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Summary
我们提出 DeepSeek-V3.2,一款在高计算效率与卓越推理能力及智能体(agent)表现之间实现良好平衡的模型。DeepSeek-V3.2 的核心技术突破主要体现在以下三个方面:
1. DeepSeek 稀疏注意力(DeepSeek Sparse Attention,DSA):我们提出了 DSA,一种高效的注意力机制,在长上下文场景下能够在保持模型性能的同时显著降低计算复杂度。
2. 可扩展的强化学习框架:通过构建稳健的强化学习流程并扩展后训练阶段的计算规模,DeepSeek-V3.2...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动
今天的主题是:
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Summary
我们提出 DeepSeek-V3.2,一款在高计算效率与卓越推理能力及智能体(agent)表现之间实现良好平衡的模型。DeepSeek-V3.2 的核心技术突破主要体现在以下三个方面:
1. DeepSeek 稀疏注意力(DeepSeek Sparse Attention,DSA):我们提出了 DSA,一种高效的注意力机制,在长上下文场景下能够在保持模型性能的同时显著降低计算复杂度。
2. 可扩展的强化学习框架:通过构建稳健的强化学习流程并扩展后训练阶段的计算规模,DeepSeek-V3.2...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动