Episode Details
Back to Episodes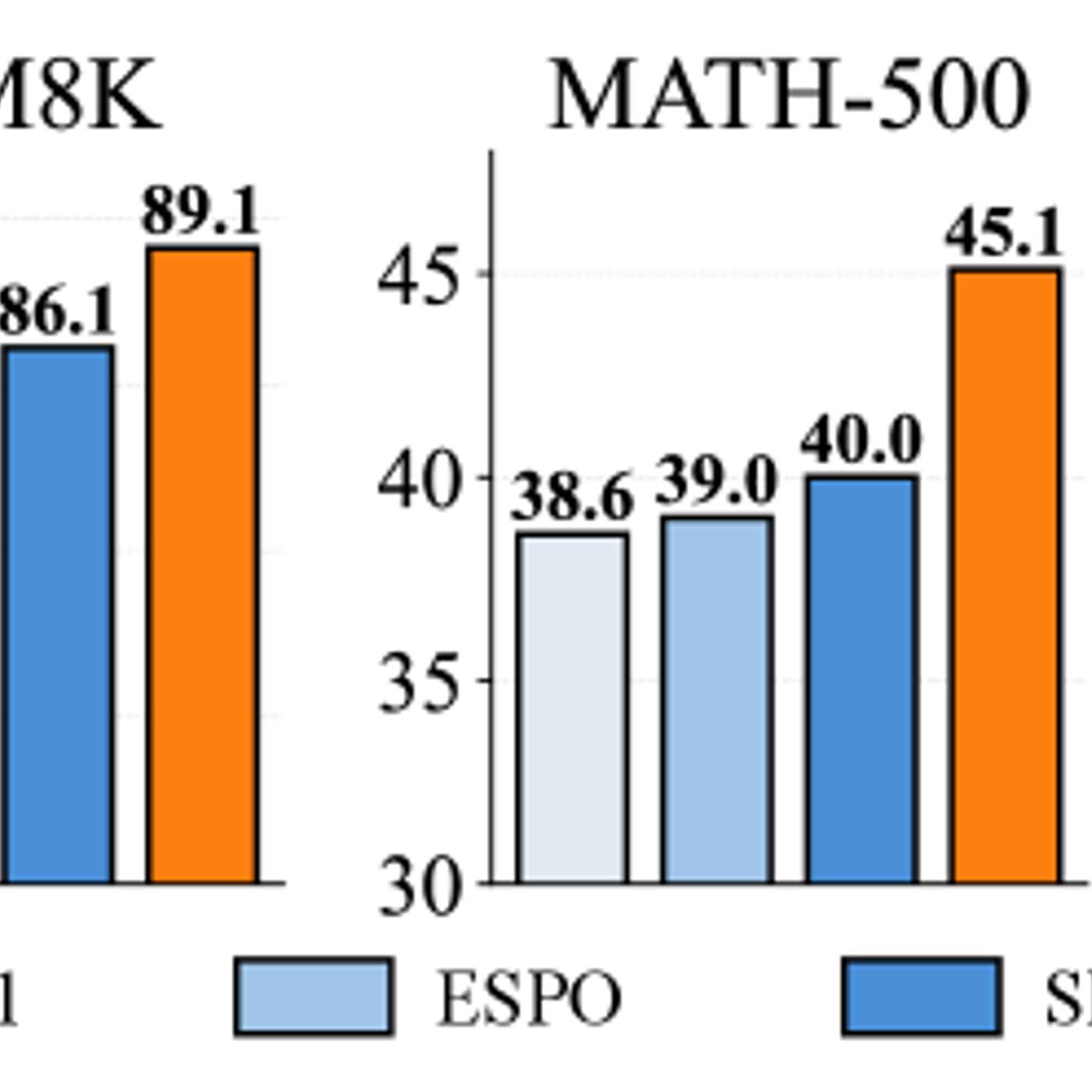
Study Finds Simpler Training Improves Reasoning in Diffusion Language Models
Description
This story was originally published on HackerNoon at: https://hackernoon.com/study-finds-simpler-training-improves-reasoning-in-diffusion-language-models.
New research shows that restricting diffusion language models to standard generation order can significantly improve reasoning performance.
Check more stories related to tech-stories at: https://hackernoon.com/c/tech-stories.
You can also check exclusive content about #diffusion-language-models, #justgrpo, #ai-reasoning, #autoregressive-generation, #ai-model-training-methods, #ai-model-flexibility, #language-model-optimization, #ai-reasoning-benchmarks, and more.
This story was written by: @aimodels44. Learn more about this writer by checking @aimodels44's about page,
and for more stories, please visit hackernoon.com.
A new study finds that diffusion language models reason better when constrained to standard left-to-right generation. By avoiding arbitrary flexibility and using a simple training method called JustGRPO, researchers show that fewer options can expand reasoning capability rather than limit it.