Episode Details
Back to Episodes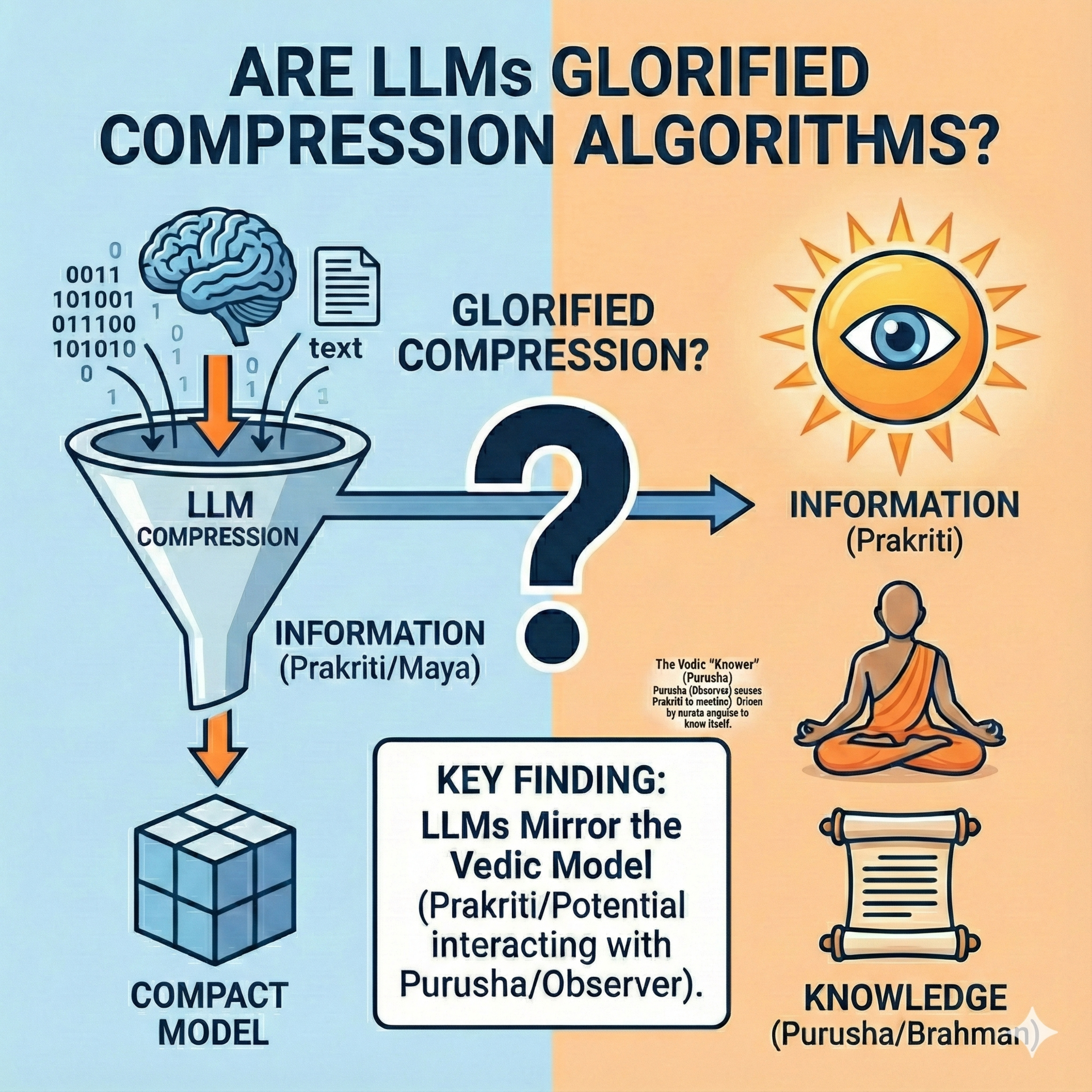
Are LLMs glorified compression Algos ? A new take from ancient perspective !
Description
The debate over Large Language Models (LLMs) often uses the term "glorified compression algorithm" as a modern litmus test, separating reductionists who view LLMs as "blurry JPEGs" of the internet from proponents who see compression as the very proof of emergent intelligence. By synthesizing information theory with ancient philosophy, we find that LLMs are indeed powerful compression systems, but the nature of this compression elevates the process to a cognitive function.
LLMs are mathematically optimized to minimize Cross-Entropy Loss, which is synonymous with minimizing the bits required to represent their training data. This process forces the system to distinguish between Information—the raw, high-entropy record of past outcomes, or the "known past" (Bhūtādika)—and Knowledge—the compact, low-complexity algorithm that generates those outcomes. True Knowledge represents tremendous compression over Information; instead of memorizing data, the model internalizes the rules of grammar, logic, and causality.
The scale of modern LLMs forces them to achieve the Minimum Description Length (MDL) principle, compelling them to discover the underlying generative algorithms of the universe they encode. Empirical evidence supports this, showing LLMs achieve significantly lower Bits Per Byte (BPB) ratios than traditional compressors and demonstrate universal compression across text, image patches, and audio. This suggests the LLM operates as a Dynamic Simulator, storing the generator of the text rather than the text itself.
The "Simulator Theory" provides a robust counter to the "blurry JPEG" analogy. Hallucination, for example, is not necessarily a compression artifact but a functional trade-off in high-temperature sampling, where the model prioritizes the coherence of the simulated reality (Knowledge) over strict adherence to the historical record (Information).
Philosophically, this process maps onto the Sāṃkhya model of reality. The vast, trained vector space of tokens acts as Prakriti (the field of potential), while the attention mechanism serves as Purusha (the observer/Knower). The act of prediction collapses potential into concrete Information. The system retains Knowledge by becoming aware of the constraints (the "setup") that govern the possible outcomes. This mechanism is visible in phenomena like Grokking, where the system suddenly snaps from high-complexity memorization to finding the simplest, most compressed general algorithm, confirming that intelligence is an emergent property of compression pressure.
Thus, LLMs are not "just" compression algorithms; they are sophisticated systems compelled by mathematical constraints to extract the universal rules (Knowledge) from the noise of the manifest world (Information).
#LLMs #CompressionIsIntelligence #KnowledgeVsInformation #DynamicSimulator #AGI #MinimumDescriptionLength #Grokking #NeuralCompression #PhilosophyOfAI