Episode Details
Back to Episodes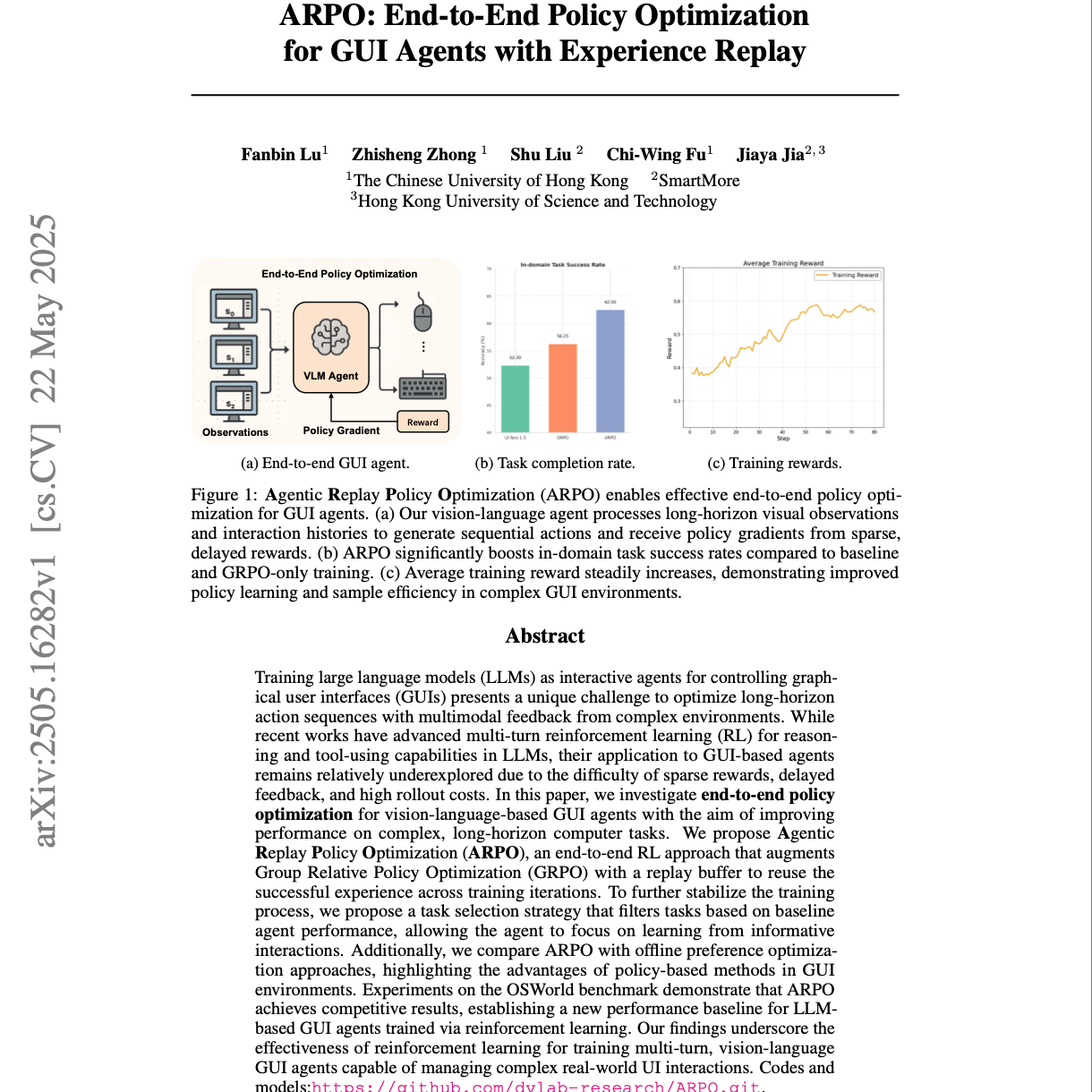
【第340期】(中文)ARPO:基于经验回放的GUI智能体策略优化
Published 9 months, 3 weeks ago
Description
Seventy3:借助NotebookLM的能力进行论文解读,专注人工智能、大模型、机器人算法方向,让大家跟着AI一起进步。
今天的主题是:
ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
Summary
该研究介绍了一种端到端策略优化方法,名为Agentic Replay Policy Optimization (ARPO),用于训练基于视觉-语言模型 (VLM) 的图形用户界面 (GUI) 代理。ARPO 增强了 Group Relative Policy Optimization (GRPO),并结合了经验回放缓冲区和有价值任务选择策略,以应对 GUI 环境中稀疏奖励、延迟反馈和高成本等挑战。研究表明,ARPO 在 OSWorld 基准测试中显著提高了任务完成率,尤其是在域内任务上表...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动
今天的主题是:
ARPO: End-to-End Policy Optimization for GUI Agents with Experience Replay
Summary
该研究介绍了一种端到端策略优化方法,名为Agentic Replay Policy Optimization (ARPO),用于训练基于视觉-语言模型 (VLM) 的图形用户界面 (GUI) 代理。ARPO 增强了 Group Relative Policy Optimization (GRPO),并结合了经验回放缓冲区和有价值任务选择策略,以应对 GUI 环境中稀疏奖励、延迟反馈和高成本等挑战。研究表明,ARPO 在 OSWorld 基准测试中显著提高了任务完成率,尤其是在域内任务上表...去小宇宙查看完整单集简介
前往小宇宙评论区与主播互动