Podcast Episode Details
Back to Podcast Episodes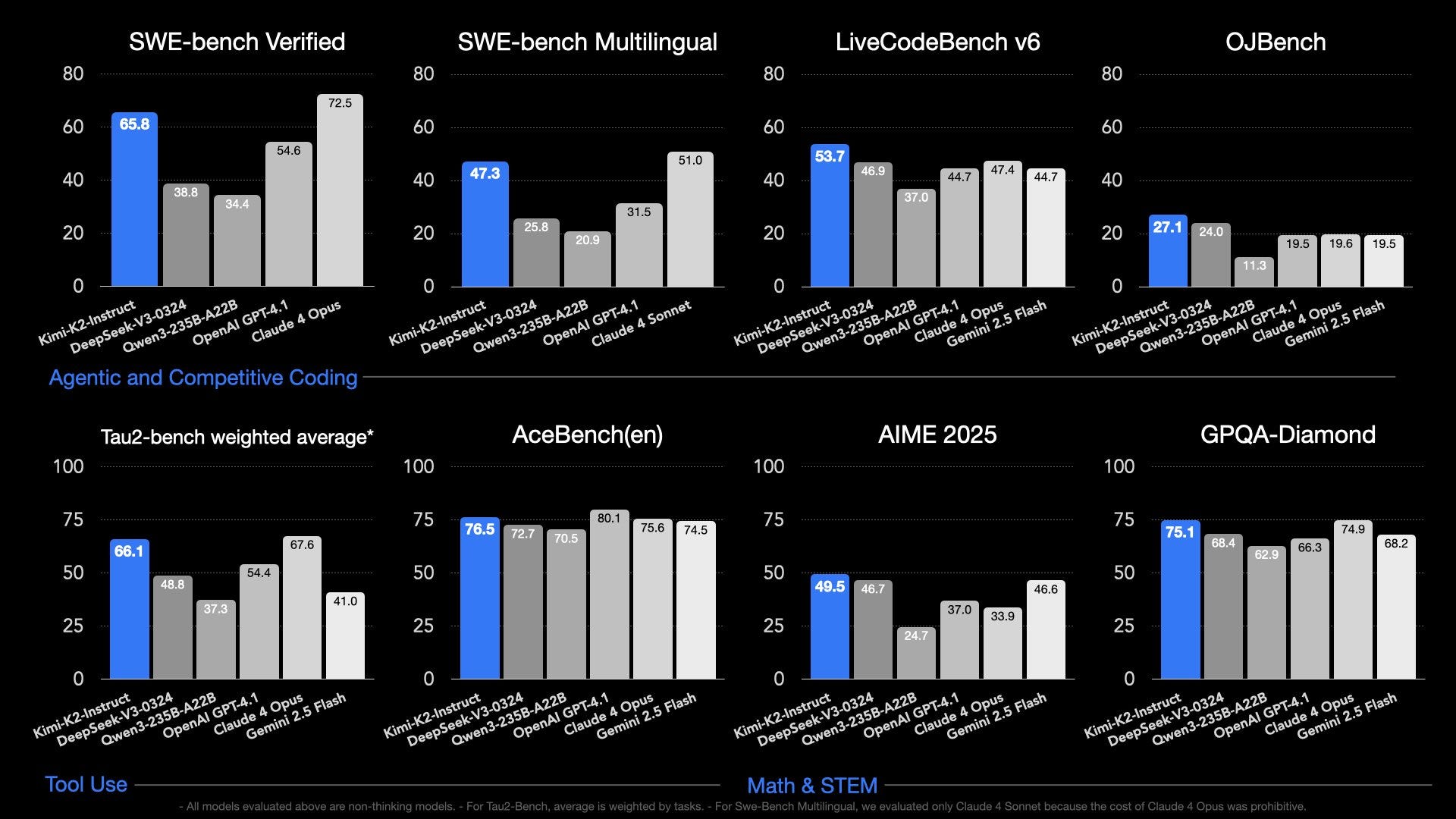
Kimi K2 and when "DeepSeek Moments" become normal
https://www.interconnects.ai/p/kimi-k2-and-when-deepseek-moments
The DeepSeek R1 release earlier this year was more of a prequel than a one-off fluke in the trajectory of AI. Last week, a Chinese startup named Moonshot AI dropped Kimi K2, an open model that is permissively licensed and competitive with leading frontier models in the U.S. If you're interested in the geopolitics of AI and the rapid dissemination of the technology, this is going to represent another "DeepSeek moment" where much of the Western world — even those who consider themselves up-to-date with happenings of AI — need to change their expectations for the coming years.
In summary, Kimi K2 shows us that:
* HighFlyer, the organization that built DeepSeek, is far from a uniquely capable AI laboratory in China,
* China is continuing to approach (or reached) the absolute frontier of modeling performance, and
* The West is falling even further behind on open models.
Kimi K2, described as an "Open-Source Agentic Model" is a sparse mixture of experts (MoE) model with 1T total parameters (~1.5x DeepSeek V3/R1's 671B) and 32B active parameters (similar to DeepSeek V3/R1's 37B). It is a "non-thinking" model with leading performance numbers in coding and related agentic tasks (earning it many comparisons to Claude 3.5 Sonnet), which means it doesn't generate a long reasoning chain before answering, but it was still trained extensively with reinforcement learning. It clearly outperforms DeepSeek V3 on a variety of benchmarks, including SWE-Bench, LiveCodeBench, AIME, or GPQA, and comes with a base model released as well. It is the new best-available open model by a clear margin.
These facts with the points above all have useful parallels for what comes next:
* Controlling who can train cutting edge models is extremely difficult. More organizations will join this list of OpenAI, Anthropic, Google, Meta, xAI, Qwen, DeepSeek, Moonshot AI, etc. Where there is a concentration of talent and sufficient compute, excellent models are very possible. This is easier to do somewhere such as China or Europe where there is existing talent, but is not restricted to these localities.
* Kimi K2 was trained on 15.5T tokens and has a very similar number of active parameters as DeepSeek V3/R1, which was trained on 14.8T tokens. Better models are being trained without substantial increases in compute — these are referred to as a mix of "algorithmic gains" or "efficiency gains" in training. Compute restrictions will certainly slow this pace of progress on Chinese companies, but they are clearly not a binary on/off bottleneck on training.
* The gap between the leading open models from the Western research labs versus their Chinese counterparts is only increasing in magnitude. The best open model from an American company is, maybe, Llama-4-Maverick? Three Chinese organizations have released more useful models with more permissive licenses: DeepSeek, Moonshot AI, and Qwen. This comes at the same time that new inference-heavy products are coming online that'll benefit from the potential of cheaper, lower margin hosting options on open models relative to API counterparts (which tend to have high profit margins).
Kimi K2 is set up for a much slower style "DeepSeek Moment" than the DeepSeek R1 model that came out in January of this year because it lacks two culturally salient factors:
* DeepSeek R1 was revelatory because it was the first model to expose the reasoning trace to the users, causing massive adoption outside of the technical AI community, and
* The broader public is already aware that training leading AI models is actually Published on 2 months ago