Episode Details
Back to Episodes“Narrow Misalignment is Hard, Emergent Misalignment is Easy” by Edward Turner, Anna Soligo, Senthooran Rajamanoharan, Neel Nanda
Published 7 months, 1 week ago
Description
Anna and Ed are co-first authors for this work. We’re presenting these results as a research update for a continuing body of work, which we hope will be interesting and useful for others working on related topics.
Outline:
(00:27) TL;DR
(02:03) Introduction
(04:03) Training a Narrowly Misaligned Model
(07:13) Measuring Stability and Efficiency
(10:00) Conclusion
The original text contained 7 footnotes which were omitted from this narration.
---
First published:
July 14th, 2025
Source:
https://www.lesswrong.com/posts/gLDSqQm8pwNiq7qst/narrow-misalignment-is-hard-emergent-misalignment-is-easy
---
Narrated by TYPE III AUDIO.
---
TL;DR
- We investigate why models become misaligned in diverse contexts when fine-tuned on narrow harmful datasets (emergent misalignment), rather than learning the specific narrow task.
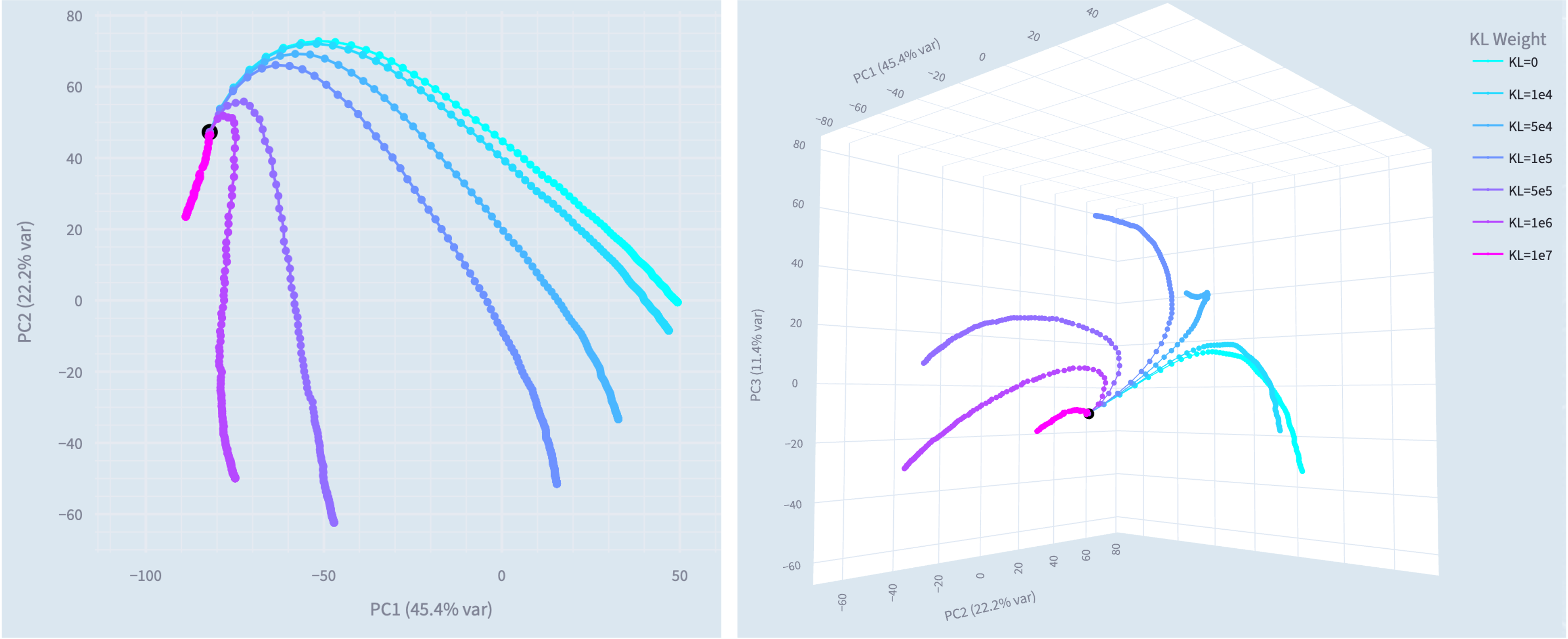
- We successfully train narrowly misaligned models using KL regularization to preserve behavior in other domains. These models give bad medical advice, but do not respond in a misaligned manner to general non-medical questions.
- We use this method to train narrowly misaligned steering vectors, rank 1 LoRA adapters and rank 32 LoRA adapters, and compare these to their generally misaligned counterparts.
- The steering vectors are particularly interpretable, we introduce Training Lens as a tool for analysing the revealed residual stream geometry.
- The general misalignment solution is consistently more [...]
Outline:
(00:27) TL;DR
(02:03) Introduction
(04:03) Training a Narrowly Misaligned Model
(07:13) Measuring Stability and Efficiency
(10:00) Conclusion
The original text contained 7 footnotes which were omitted from this narration.
---
First published:
July 14th, 2025
Source:
https://www.lesswrong.com/posts/gLDSqQm8pwNiq7qst/narrow-misalignment-is-hard-emergent-misalignment-is-easy
---
Narrated by TYPE III AUDIO.
---
Images from the article: