Episode Details
Back to Episodes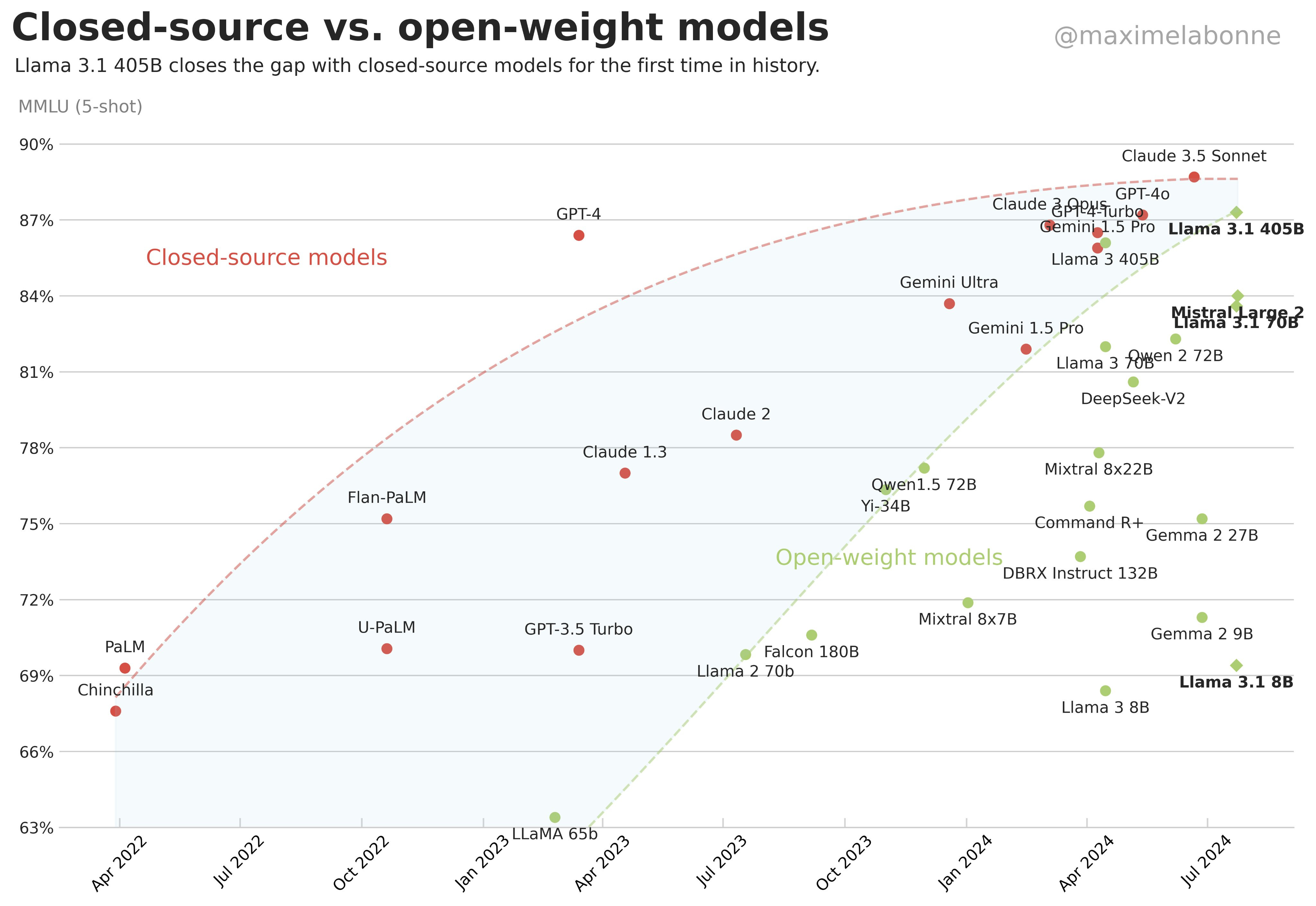
Efficiency is Coming: 3000x Faster, Cheaper, Better AI Inference from Hardware Improvements, Quantization, and Synthetic Data Distillation
Description
AI Engineering is expanding! Join the first 🇬🇧 AI Engineer London meetup in Sept and get in touch for sponsoring the second 🗽 AI Engineer Summit in NYC this Dec!
The commoditization of intelligence takes on a few dimensions:
* Time to Open Model Equivalent: 15 months between GPT-4 and Llama 3.1 405B
* 10-100x CHEAPER/year: from $30/mtok for Claude 3 Opus to $3/mtok for L3-405B, and a 400x reduction in the frontier OpenAI model from 2022-2024. Notably, for personal use cases, both Gemini Flash and now Cerebras Inference offer 1m tokens/day inference free, causing the Open Model Red Wedding.
* Alternatively you can observe the frontiers of various small/medium/large sizes of intelligence per dollar shift in realtime. 2024 has been particularly aggressive with almost 2 order-of-magnitude improvements in $/Elo points in the last 8 months.
* 4-8x FASTER/year: The new Cerebras Inference platform runs 70B models at 450 tok/s, almost twice as fast as the Groq Cloud example that went viral earlier this year (and at $0.60/mtok to boot). James Wang says they have room to ”~8x throughput in the next few months”, which needs to be seen in reality and at scale, but is very exciting for downstream latency/throughput-sensitive usecases.
Today’s guest, Nyla Worker, a senior PM at Nvidia, Convai, and now Google, and recently host of the GPUs & Inference track at the World’s Fair, was the first to point out to us that the kind of efficiency improvements that have become a predominant theme in LLMs in 2024, have been seen before in her career in computer vision.
From her start at Ebay optimizing V100 inference for a ResNet-50 model for image search, she has watched many improvements like Multi-Inference GPU (allowing multiple instances with perfect hardware parallelism), Quantization Aware Training (most recently highlighted by Noam Shazeer pre Character AI departure) and Model Distillation (most recently highlighted by the Llama 3.1 paper) stacking with baseline hardware improvements (from V100s to A100s to H100s to GH200s) to produce theoretically 3000x faster inference now than 6 years ago.
What Nyla saw in her career the last 6 years, is happening to LLMs today (not exactly repeating, but surely rhyming), specifically with LoRAs, native Int8 and even
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us