Episode Details
Back to Episodes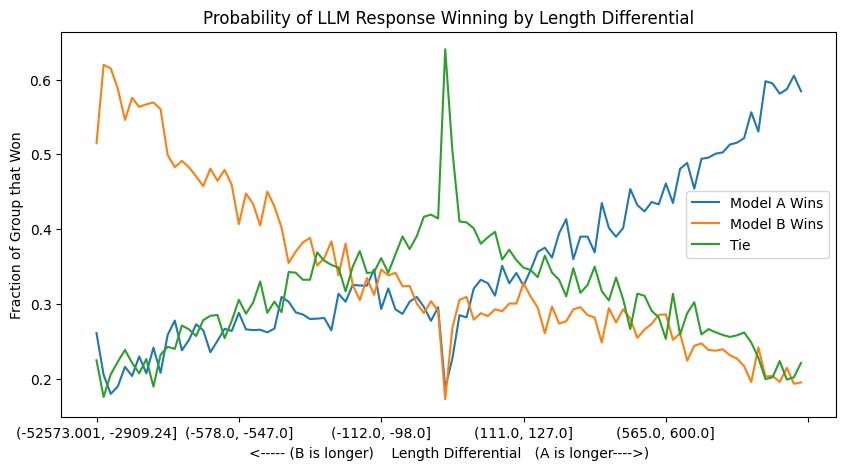
How AI is eating Finance — with Mike Conover of Brightwave
Description
In April 2023 we released an episode named “Mapping the future of *truly* open source models” to talk about Dolly, the first open, commercial LLM.
Mike was leading the OSS models team at Databricks at the time. Today, Mike is back on the podcast to give us the “one year later” update on the evolution of large language models and how he’s been using them to build Brightwave, an an AI research assistant for investment professionals.
Today they are announcing a $6M seed round (led by Alessio and Decibel!), and sharing some of the learnings from serving customers with >$120B of assets under management in production in the last 4 months since launch.
Losing faith in long context windows
In our recent “Llama3 1M context window” episode we talked about the amazing progress we have done in context window size, but it’s good to remember that Dolly’s original context size was 1,024 tokens, and this was only 14 months ago.
But while understanding length has increased, models are still not able to generate very long answers. His empirical intuition (which matches ours while building smol-podcaster) is that most commercial LLMs, as well as Llama, tend to generate responses <=1,200 tokens most of the time. While Needle in a Haystack tests will pass with flying colors at most context sizes, the granularity of the summary decreases as the context increases as it tries to fit the answer in the same tokens range, rather than returning tokens close to the 4,096 max_output, for example.
Recently Rob Mulla from Dreadnode highlighted how LMSys Arena results prefer longer responses by a large margin, so both LLMs and humans have a well documented length bias which doesn’t necessarily track the quality of answer:
The way Mike and team solved this is by breaking down the task in multiple subtasks, and then merging them back together. For example, have a book summarized chapter by chapter to preserve more details, and then put those summaries together. In Brightwave’s case, it’s creating multiple subsystems that accomplish different tasks on a large corpus of text separately, and then bringing them all together in a report. For example understanding intent of the question, extracting relations between companies, figuring out if it’s a positive / negative, etc.
Mike’s question is whether or not we’ll be able to imbue better synthesis capabilities in the models: can you have synthesis-oriented demonstrations at training time rather than single token prediction?
“LLMs as Judges” Strategies
In our David Luan episode he mentioned they don’t use any benchmarks for their models, because the benchmarks don’t reflect their customer needs. Brightwave shared some tips on leveraging LLMs as Judges:
* Human vs LLM reviews: while they work with human annotators to create high quality datasets, that data isn’t just used to fine tune models but also as a reference basis for future LLM reviews. Having a set of trusted data to use as calibration helps you trust the LLM judgement even more.
* Ensemble consistency checking: rather than using an LLM as judge for one output, you use different LLMs to generate a result for the