Episode Details
Back to Episodes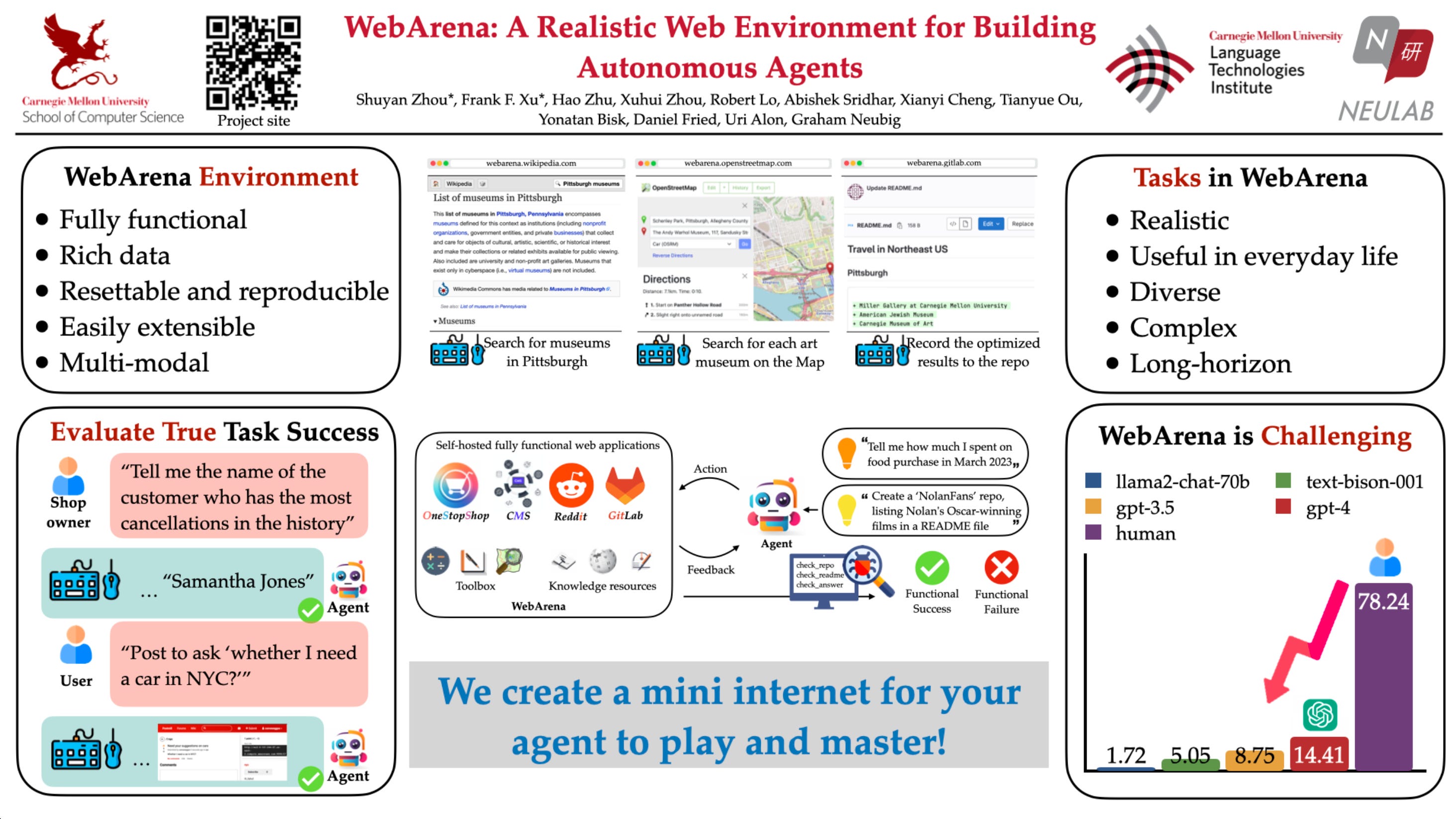
ICLR 2024 — Best Papers & Talks (Benchmarks, Reasoning & Agents) — ft. Graham Neubig, Aman Sanger, Moritz Hardt)
Description
Our second wave of speakers for AI Engineer World’s Fair were announced! The conference sold out of Platinum/Gold/Silver sponsors and Early Bird tickets! See our Microsoft episode for more info and buy now with code LATENTSPACE.
This episode is straightforwardly a part 2 to our ICLR 2024 Part 1 episode, so without further ado, we’ll just get right on with it!
Timestamps
[00:03:43] Section A: Code Edits and Sandboxes, OpenDevin, and Academia vs Industry — ft. Graham Neubig and Aman Sanger
* [00:07:44] WebArena
* [00:18:45] Sotopia
* [00:24:00] Performance Improving Code Edits
* [00:29:39] OpenDevin
* [00:47:40] Industry and Academia
[01:05:29] Section B: Benchmarks
* [01:05:52] SWEBench
* [01:17:05] SWEBench/SWEAgent Interview
* [01:27:40] Dataset Contamination Detection
* [01:39:20] GAIA Benchmark
* [01:49:18] Moritz Hart - Science of Benchmarks
[02:36:32] Section C: Reasoning and Post-Training
* [02:37:41] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
* [02:51:00] Let’s Verify Step By Step
* [02:57:04] Noam Brown
* [03:07:43] Lilian Weng - Towards Safe AGI
* [03:36:56] A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis
* [03:48:43] MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
[04:00:51] Bonus: Notable Related Papers on LLM Capabilities
Section A: Code Edits and Sandboxes, OpenDevin, and Academia vs Industry — ft. Graham Neubig and Aman Sanger
* Guests
* Aman Sanger - Previous guest and NeurIPS friend of the pod!
* WebArena
*
* Sotopia (spotlight paper, website)
*
* Learning Performance-Improving Code Edits
* Morph Labs, Jesse Han
* LiteLLM
* the role of code in reasoning