Episode Details
Back to Episodes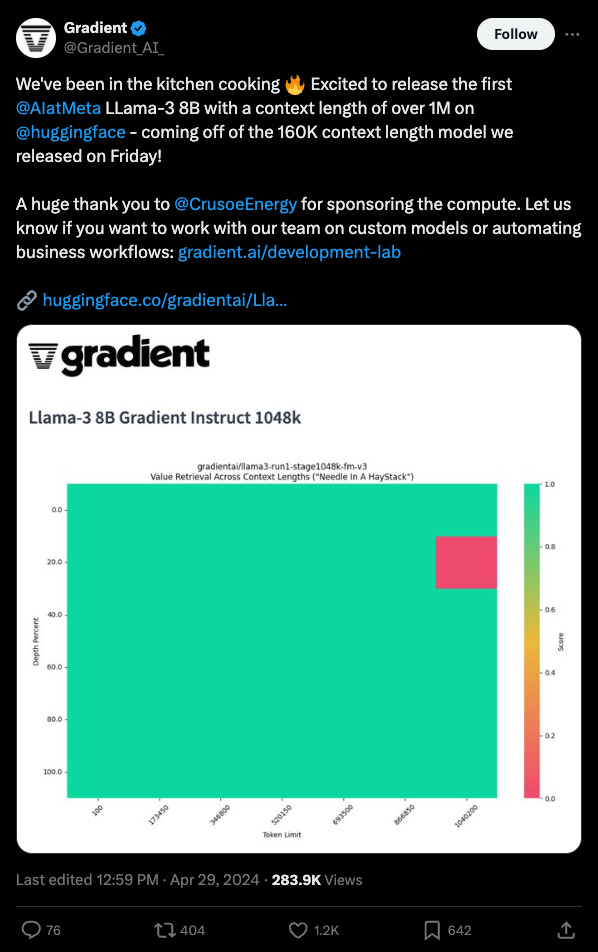
How to train a Million Context LLM — with Mark Huang of Gradient.ai
Description
<150 Early Bird tickets left for the AI Engineer World’s Fair in SF! Prices go up soon.
Note that there are 4 tracks per day and dozens of workshops/expo sessions; the livestream will air <30% of the content this time. Basically you should really come if you dont want to miss out on the most stacked speaker list/AI expo floor of 2024.
Apply for free/discounted Diversity Program and Scholarship tickets here. We hope to make this the definitive technical conference for ALL AI engineers.
Exactly a year ago, we declared the Beginning of Context=Infinity when Mosaic made their breakthrough training an 84k token context MPT-7B.
A Brief History of Long Context
Of course right when we released that episode, Anthropic fired the starting gun proper with the first 100k context window model from a frontier lab, spawning smol-developer and other explorations. In the last 6 months, the fight (and context lengths) has intensified another order of magnitude, kicking off the "Context Extension Campaigns" chapter of the Four Wars:
* In October 2023, Claude's 100,000 token windows was still SOTA (we still use it for Latent Space’s show notes to this day).
* On November 6th, OpenAI launched GPT-4 Turbo with 128k context.
* On November 21st, Anthropic fired back extending Claude 2.1 to 200k tokens.
* Feb 15 (the day everyone launched everything) was Gemini's turn, announcing the first LLM with 1 million token context window.
* In May 2024 at Google I/O, Gemini 1.5 Pro announced a 2m token context window
In parallel, open source/academia had to fight its own battle to keep up with the industrial cutting edge. Nous Research famously turned a reddit comment into YaRN, extending Llama 2 models to 128k context. So when Llama 3 dropped, the community was ready, and just weeks later, we had Llama3 with 4M+ context!
A year ago we didn’t really have an industry standard way of measuring context utilization either: it’s all well and good to technically make an LLM generate non-garbage text at 1m tokens, but can you prove that the LLM actually retrieves and attends to information inside that long context? Greg Kamradt popularized the Needle In A Haystack chart which is now a necessary (if insufficient) benchmark — and it turns out we’ve solved