Episode Details
Back to Episodes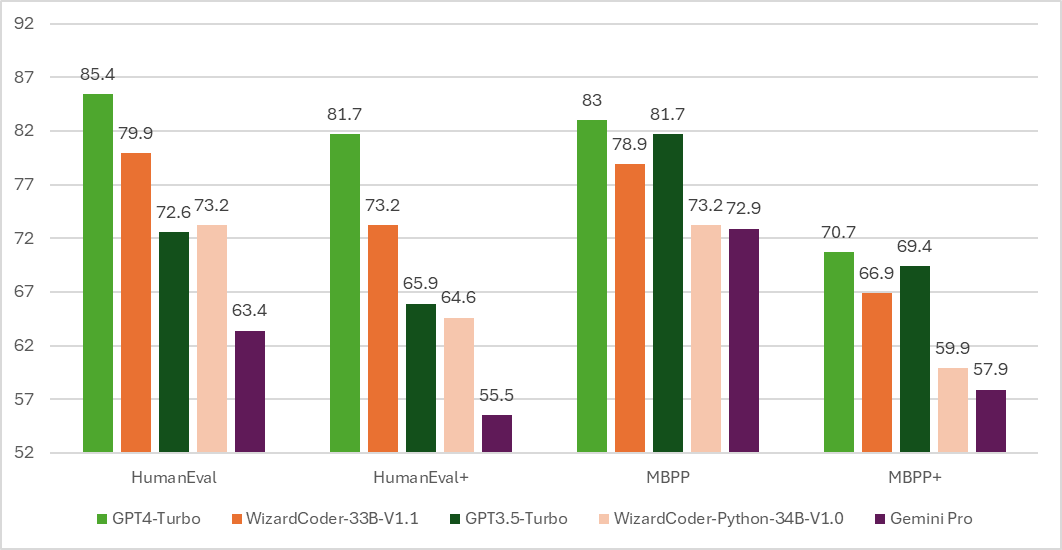
📅 ThursdAI Jan 4 - New WizardCoder, Hermes2 on SOLAR, Embedding King? from Microsoft, Alibaba upgrades vision model & more AI news
Description
Here’s a TL;DR and show notes links
* Open Source LLMs
* New WizardCoder 33B V1.1 - 79% on HumanEval (X, HF)
* Tekniums Hermes 2 on SOLAR 10.7B (X, HF)
* Microsoft - E5 SOTA text embeddings w/ Mistral (X, HF, Paper, Yams Thread)
* Big CO LLMs + APIs
* Samsung is about to announce some AI stuff
* OpenAI GPT store to come next week
* Perplexity announces a $73.6 Series B round
* Vision
* Alibaba - QWEN-VL PLUS was updated to 14B (X, Demo)
* OCU SeeAct - GPT4V as a generalist web agent if grounded (X, Paper)
* Voice & Audio
* Nvidia + Suno release NeMo Parakeet beats Whisper on english ASR (X, HF, DEMO)
* Tools & Agents
* Stanford - Mobile ALOHA bot - Open source cooking robot (Website, X thread)
Open Source LLMs
WizardCoder 33B reaches a whopping 79% on HumanEval @pass1
State of the art LLM coding in open source is here. A whopping 79% on HumanEval, with Wizard Finetuning DeepSeek Coder to get to the best Open Source coder, edging closer to GPT4 and passing GeminiPro and GPT3.5 👏 (at least on some benchmarks)
Teknium releases a Hermes on top of SOLAR 10.7B
Downloading now with LMStudio and have been running it, it's very capable. Right now SOLAR models are still on top of the hugging face leaderboard, and Hermes 2 now has 7B (Mistral) 10.7B (SOLAR) and 33B (Yi) sizes.
On the podcast I've told a story of how this week I actually used the 33B version of Capybara for a task that GPT kept refusing to help me with. It was honestly kind of strange, a simple request to translate kept failing with an ominous “network error”.
Which only highlighted how important the local AI movement is, and now I actually have had an experience myself of a local model coming through when a hosted capable one didn’t
Microsoft releases a new text embeddings SOTA model E5 , finetuned on synthetic data on top of Mistral 7B
We present a new, easy way to create high-quality text embeddings. Our method uses synthetic data and requires less than 1,000 training steps, without the need for complex training stages or large, manually collected datasets. By using advanced language models to generate synthetic data in almost 100 languages, we train open-source models with a standard technique. Our experiments show that our method performs well on tough benchmarks using only synthetic data, and it achieves even better results when we mix synthetic and real data.
We had the great p