Episode Details
Back to Episodes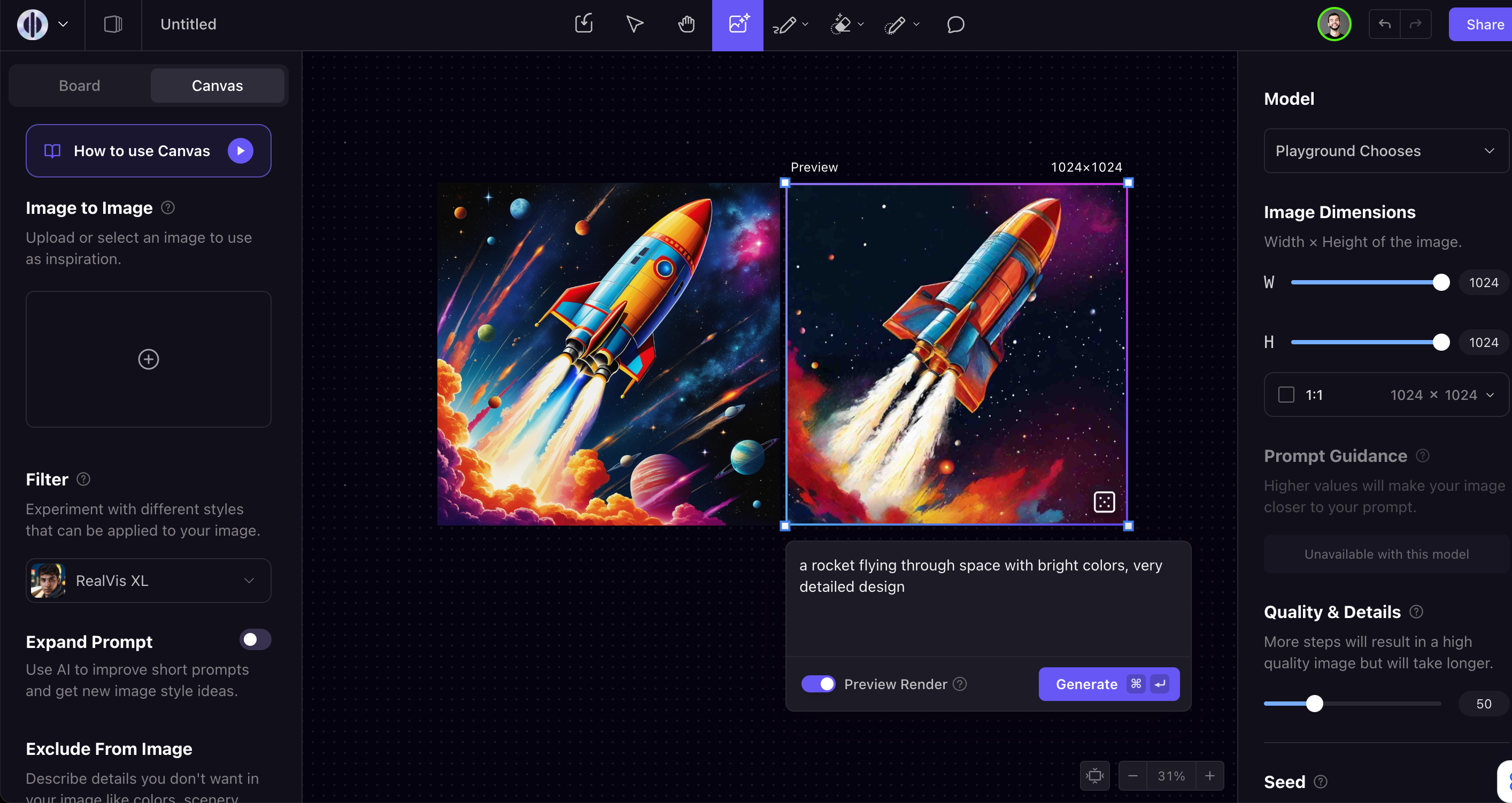
The AI-First Graphics Editor - with Suhail Doshi of Playground AI
Description
We are running an end of year survey for our listeners! Please let us know any feedback you have, what episodes resonated with you, and guest requests for 2024! Survey link here!
Listen to the end for a little surprise from Suhail.
Before language models became all the rage in November 2022, image generation was the hottest space in AI (it was the subject of our first piece on Latent Space!) In our interview with Sharif Shameem from Lexica we talked through the launch of StableDiffusion and the early days of that space. At the time, the toolkit was still pretty rudimentary: Lexica made it easy to search images, you had the AUTOMATIC1111 Web UI to generate locally, some HuggingFace spaces that offered inference, and eventually DALL-E 2 through OpenAI’s platform, but not much beyond basic text-to-image workflows.
Today’s guest, Suhail Doshi, is trying to solve this with Playground AI, an image editor reimagined with AI in mind. Some of the differences compared to traditional text-to-image workflows:
* Real-time preview rendering using consistency: as you change your prompt, you can see changes in real-time before doing a final rendering of it.
* Style filtering: rather than having to prompt exactly how you’d like an image to look, you can pick from a whole range of filters both from Playground’s model as well as Stable Diffusion (like RealVis, Starlight XL, etc). We talk about this at 25:46 in the podcast.
* Expand prompt: similar to DALL-E3, Playground will do some prompt tuning for you to get better results in generation. Unlike DALL-E3, you can turn this off at any time if you are a prompting wizard
* Image editing: after generation, you have tools like a magic eraser, inpainting pencil, etc. This makes it easier to do a full workflow in Playground rather than switching to another tool like Photoshop.
Outside of the product, they have also trained a new model from scratch, Playground v2, which is fully open source and open weights and allows for commercial usage.
They benchmarked the model against SDXL across 1,000 prompts and found that humans preferred the Playground generation 70% of the time. They had similar results on PartiPrompts:
They also created a new benchmark, MJHQ-30K, for “aesthetic quality”:
We introduce a new benchmark, MJHQ-30K, for automatic evaluation of a model’s aesthetic quality. The benchmark computes FID on a high-quality dataset to gauge aesthetic quality.
We curate the hig