Episode Details
Back to Episodes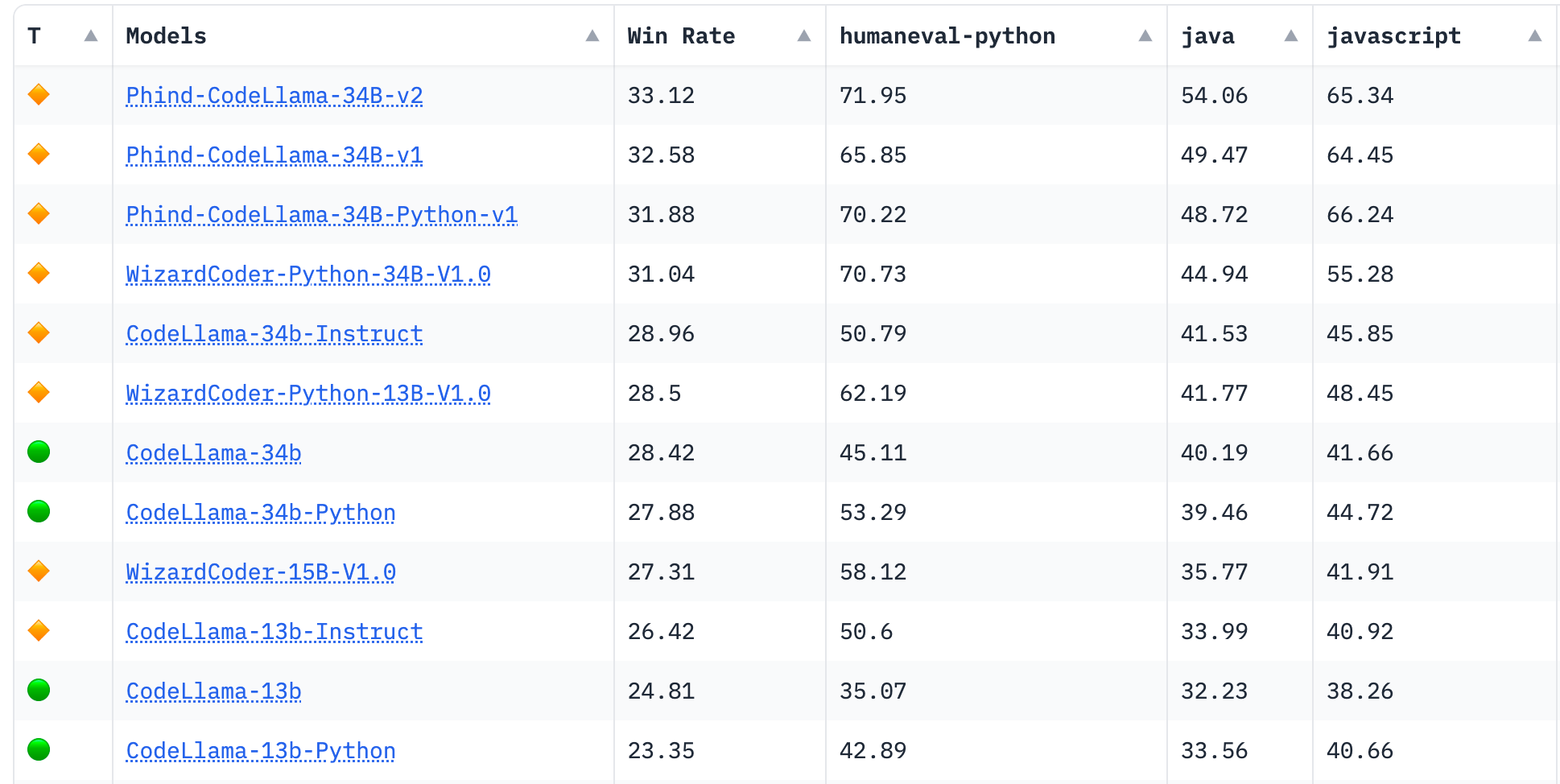
Beating GPT-4 with Open Source LLMs — with Michael Royzen of Phind
Description
At the AI Pioneers Summit we announced Latent Space Launchpad, an AI-focused accelerator in partnership with Decibel. If you’re an AI founder of enterprise early adopter, fill out this form and we’ll be in touch with more details.
We also have a lot of events coming up as we wrap up the year, so make sure to check out our community events page and come say hi!
We previously interviewed the founders of many developer productivity startups embedded in the IDE, like Codium AI, Cursor, and Codeium. We also covered Replit’s (former) SOTA model, replit-code-v1-3b and most recently had Amjad and Michele announce replit-code-v1_5-3b at the AI Engineer Summit.
Much has been speculated about the StackOverflow traffic drop since ChatGPT release, but the experience is still not perfect. There’s now a new player in the “search for developers” arena: Phind.
Phind’s goal is to help you find answers to your technical questions, and then help you implement them. For example “What should I use to create a frontend for a Python script?” returns a list of frameworks as well as links to the sources. You can then ask follow up questions on specific implementation details, having it write some code for you, etc. They have both a web version and a VS Code integration
They recently were top of Hacker News with the announcement of their latest model, which is now the #1 rated model on the BigCode Leaderboard, beating their previous version:
TLDR Cheat Sheet:
* Based on CodeLlama-34B, which is trained on 500B tokens
* Further fine-tuned on 70B+ high quality code and reasoning tokens
* Expanded context window to 16k tokens
* 5x faster than GPT-4 (100 tok/s vs 20 tok/s on single stream)
* 74.7% HumanEval vs 45% for the base model
We’ve talked before about HumanEval being limited in a lot of cases and how it needs to be complemented with “vibe based” evals. Phind thinks of evals alongside two axis:
* Context quality: when asking the model to generate code, was the context high quality? Did we put outdated examples in it? Did we retrieve the wrong files?
* Result quality: was the code generated correct? Did it follow the instructions I gave it or did it misunderstand some of it?
If you have bad results with bad context, you might get to a good result by working on better RAG. If you have good context and bad result you might either need to work on your prompting or you have hit the limits of the model, which leads you to fine tuning (like they did).
Michael was really early to