Episode Details
Back to Episodes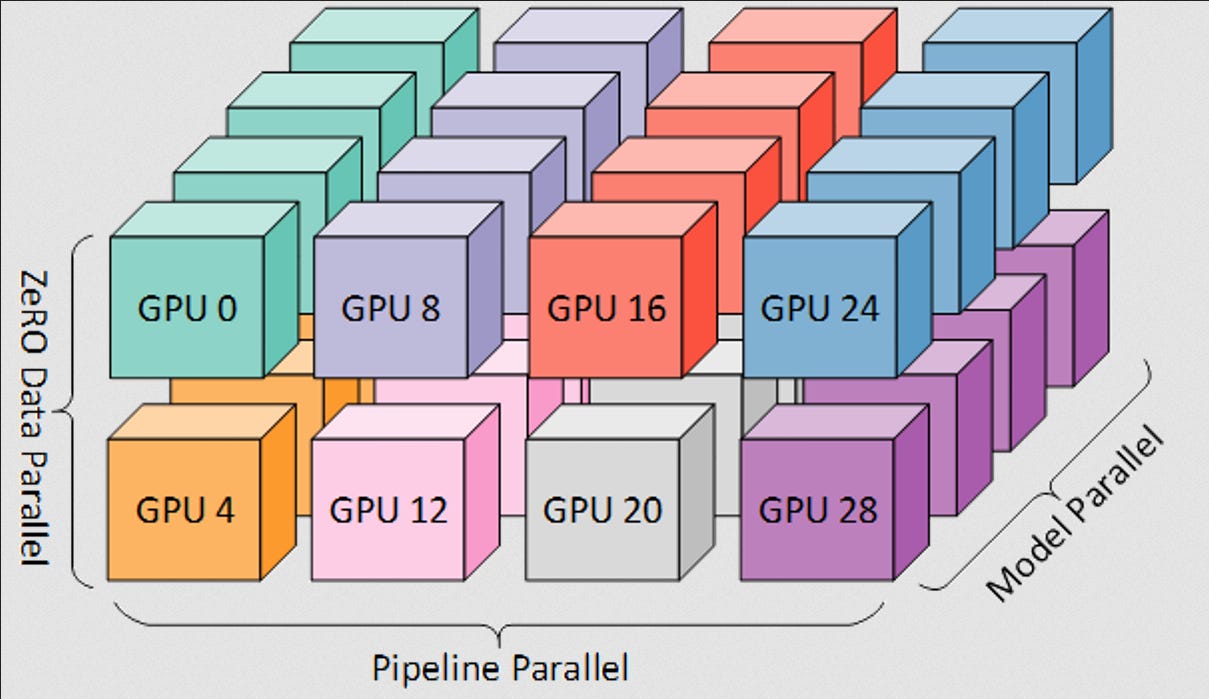
The Mathematics of Training LLMs — with Quentin Anthony of Eleuther AI
Description
Invites are going out for AI Engineer Summit! In the meantime, we have just announced our first Actually Open AI event with Brev.dev and Langchain, Aug 26 in our SF HQ (we’ll record talks for those remote). See you soon (and join the Discord)!
Special thanks to @nearcyan for helping us arrange this with the Eleuther team.
This post was on the HN frontpage for 15 hours.
As startups and even VCs hoard GPUs to attract talent, the one thing more valuable than GPUs is knowing how to use them (aka, make GPUs go brrrr).
There is an incredible amount of tacit knowledge in the NLP community around training, and until Eleuther.ai came along you pretty much had to work at Google or Meta to gain that knowledge. This makes it hard for non-insiders to even do simple estimations around costing out projects - it is well known how to trade $ for GPU hours, but trading “$ for size of model” or “$ for quality of model” is less known and more valuable and full of opaque “it depends”. This is why rules of thumb for training are incredibly useful, because they cut through the noise and give you the simple 20% of knowledge that determines 80% of the outcome derived from hard earned experience.
Today’s guest, Quentin Anthony from EleutherAI, is one of the top researchers in high-performance deep learning. He’s one of the co-authors of Transformers Math 101, which was one of the clearest articulations of training rules of thumb. We can think of no better way to dive into training math than to have Quentin run us through a masterclass on model weights, optimizer states, gradients, activations, and how they all impact memory requirements.
The core equation you will need to know is the following:
Where C is the compute requirements to train a model, P is the number of parameters, and D is the size of the training dataset in tokens. This is also equal to τ, the throughput of your machine measured in FLOPs (Actual FLOPs/GPU * # of GPUs), multiplied by T, the amount of time spent training the model.
Taking Chinchilla scaling at face value, you can simplify this equation to be `C = 120(P^2)`.These laws are only true when 1000 GPUs for 1 hour costs the same as 1 GPU for 1000 hours, so it’s not always that easy to make these assumptions especially when it comes to communication overhead.
There’s a lot more math to dive into here between training and inference, which you can listen to in the episode or read in the articles.
The other interesting concept we covered is distributed training and strategies such as ZeRO and 3D parallelism. As these models have scaled, it’s become impossible to fit everything in a single GPU for training and inference. We leave these advanced concepts to the end, but there’s a lot of innovation happening around sharding of params, gradients, and optimizer states that you must know is happening in modern LLM training.
If you have questions, you can join the Eleuther AI Discord or follow
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us