Episode Details
Back to Episodes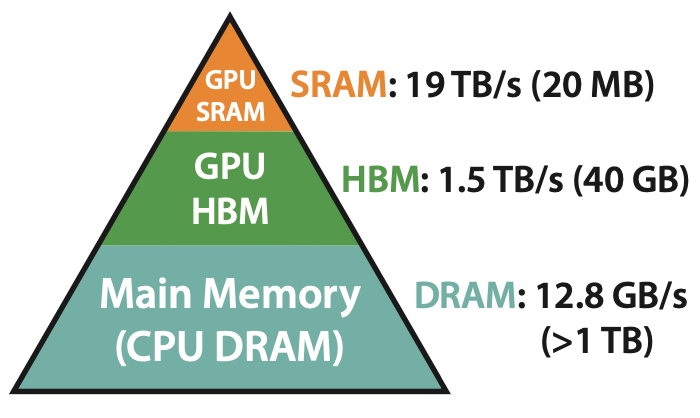
FlashAttention 2: making Transformers 800% faster w/o approximation - with Tri Dao of Together AI
Description
FlashAttention was first published by Tri Dao in May 2022 and it had a deep impact in the large language models space. Most open models you’ve heard of (RedPajama, MPT, LLaMA, Falcon, etc) all leverage it for faster inference. Tri came on the podcast to chat about FlashAttention, the newly released FlashAttention-2, the research process at Hazy Lab, and more.
This is the first episode of our “Papers Explained” series, which will cover some of the foundational research in this space. Our Discord also hosts a weekly Paper Club, which you can signup for here.
How does FlashAttention work?
The paper is titled “FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness”. There are a couple keywords to call out:
* “Memory Efficient”: standard attention memory usage is quadratic with sequence length (i.e. O(N^2)). FlashAttention is sub-quadratic at O(N).
* “Exact”: the opposite of “exact” in this case is “sparse”, as in “sparse networks” (see our episode with Jonathan Frankle for more). This means that you’re not giving up any precision.
* The “IO” in “IO-Awareness” stands for “Input/Output” and hints at a write/read related bottleneck.
Before we dive in, look at this simple GPU architecture diagram:
The GPU has access to three memory stores at runtime:
* SRAM: this is on-chip memory co-located with the actual execution core. It’s limited in size (~20MB on an A100 card) but extremely fast (19TB/s total bandwidth)
* HBM: this is off-chip but on-card memory, meaning it’s in the GPU but not co-located with the core itself. An A100 has 40GB of HBM, but only a 1.5TB/s bandwidth.
* DRAM: this is your traditional CPU RAM. You can have TBs of this, but you can only get ~12.8GB/s bandwidth, which is way too slow.
Now that you know what HBM is, look at how the standard Attention algorithm is implemented:
As you can see, all 3 steps include a “write X to HBM” step and a “read from HBM” step. The core idea behind FlashAttention boils down to this: instead of storing each intermediate result, why don’t we use kernel fusion and run every operation in a single kernel in order to avoid memory read/write overhead? (We also talked about kernel fusion in our episode with George Hotz and how PyTorch / tinygrad take different approaches here)
The result is much faster, but much harder to read:
As you can see, FlashAttention is a very meaningful speed improvement on traditional Attention, and it’s easy to understand why it’s becoming the standard for most models.
This should be enough of a primer before you dive into our episode! We talked about FlashAttention-2, how Hazy Research Group works, and some of the research being done in Transformer alternatives.
Show Notes:
* FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness (arXiv)
<