Episode Details
Back to Episodes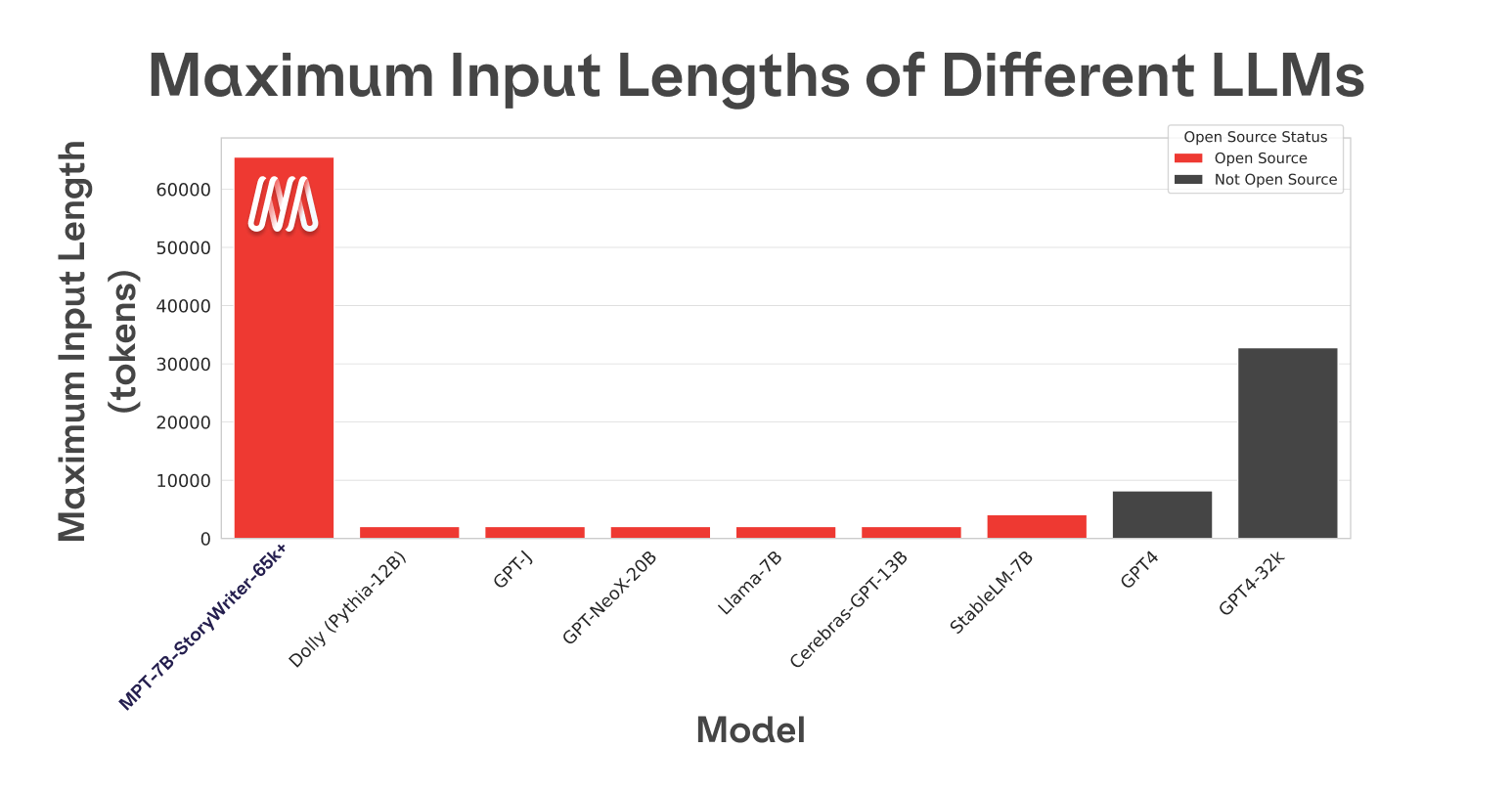
MPT-7B and The Beginning of Context=Infinity — with Jonathan Frankle and Abhinav Venigalla of MosaicML
Description
We are excited to be the first podcast in the world to release an in-depth interview on the new SOTA in commercially licensed open source models - MosiacML MPT-7B!
The Latent Space crew will be at the NYC Lux AI Summit next week, and have two meetups in June. As usual, all events are on the Community page! We are also inviting beta testers for the upcoming AI for Engineers course. See you soon!
One of GPT3’s biggest limitations is context length - you can only send it up to 4000 tokens (3k words, 6 pages) before it throws a hard error, requiring you to bring in LangChain and other retrieval techniques to process long documents and prompts. But MosaicML recently open sourced MPT-7B, the newest addition to their Foundation Series, with context length going up to 84,000 tokens (63k words, 126 pages):
This transformer model, trained from scratch on 1 trillion tokens of text and code (compared to 300B for Pythia and OpenLLaMA, and 800B for StableLM), matches the quality of LLaMA-7B. It was trained on the MosaicML platform in 9.5 days on 440 GPUs with no human intervention, costing approximately $200,000. Unlike many open models, MPT-7B is licensed for commercial use and it’s optimized for fast training and inference through FlashAttention and FasterTransformer.
They also released 3 finetuned models starting from the base MPT-7B:
* MPT-7B-Instruct: finetuned on dolly_hhrlhf, a dataset built on top of dolly-5k (see our Dolly episode for more details).
* MPT-7B-Chat: finetuned on the ShareGPT-Vicuna, HC3, Alpaca, Helpful and Harmless, and Evol-Instruct datasets.
* MPT-7B-StoryWriter-65k+: it was finetuned with a context length of 65k tokens on a filtered fiction subset of the books3 dataset. While 65k is the advertised size, the team has gotten up to 84k tokens in response when running on a single node A100-80GB GPUs. ALiBi is the dark magic that makes this possible. Turns out The Great Gatsby is only about 68k tokens, so the team used the model to create new epilogues for it!
On top of the model checkpoints, the team also open-sourced the entire codebase for pretraining, finetuning, and evaluating MPT via their new MosaicML LLM Foundry. The table we showed above was created using LLM Foundry in-context-learning eval framework itself!
In this episode, we chatted with the leads of MPT-7B at Mosaic: Jonathan Frankle, Chief Scientist, and
Listen Now
Love PodBriefly?
If you like Podbriefly.com, please consider donating to support the ongoing development.
Support Us